![]()
Alex Dejanovski
Medusa - Spotify’s Apache Cassandra backup tool is now open source
Spotify and The Last Pickle (TLP) have collaborated over the past year to build Medusa, a backup and restore system for Apache Cassandra which is now fully open sourced under the Apache License 2.0.
Challenges Backing Up Cassandra
Backing up Apache Cassandra databases is hard, not complicated. You can take manual snapshots using nodetool and move them off the node to another location. There are existing open source tools such as tablesnap, or the manual processes discussed in the previous TLP blog post “Cassandra Backup and Restore - Backup in AWS using EBS Volumes”. However they all tend to lack some features needed in production, particularly when it comes to restoring data - which is the ultimate test of a backup solution.
Providing disaster recovery for Cassandra has some interesting challenges and opportunities:
- The data in each SSTable is immutable allowing for efficient differential backups that only copy changes since the last backup.
- Each SSTable contains data that node is responsible for, and the restore process must make sure it is placed on a node that is also responsible for the data. Otherwise it may be unreachable by clients.
- Restoring to different cluster configurations, changes in the number of nodes or their tokens, requires that data be re-distributed into the new topology following Cassandra’s rules.
Introducing Medusa
Medusa is a command line backup and restore tool that understands how Cassandra works.
The project was initially created by Spotify to replace their legacy backup system. TLP was hired shortly after to take over development, make it production ready and open source it.
It has been used on small and large clusters and provides most of the features needed by an operations team.
Medusa supports:
- Backup a single node.
- Restore a single node.
- Restore a whole cluster.
- Selective restore of keyspaces and tables.
- Support for single token and vnodes clusters.
- Purging the backup set of old data.
- Full or differential backup modes.
- Automated verification of restored data.
The command line tool that uses Python version 3.6 and needs to be installed on all the nodes you want to back up. It supports all versions of Cassandra after 2.1.0 and thanks to the Apache libcloud project can store backups in a number of platforms including:
- Amazon Web Services S3.
- Google Cloud Platform GCS.
- Local file storage.
- Any of the libcloud supported providers with minimal effort.
Backup A Single Node With Medusa
Once medusa is installed and configured a node can be backed up with a single, simple command:
medusa backup --backup-name=<backup name>
When executed like this Medusa will:
- Create a snapshot using the Cassandra nodetool command.
- Upload the snapshot to your configured storage provider.
- Clear the snapshot from the local node.
Along with the SSTables, Medusa will store three meta files for each backup:
- The complete CQL schema.
- The token map, a list of nodes and their token ownership.
- The manifest, a list of backed up files with their md5 hash.
Full And Differential Backups
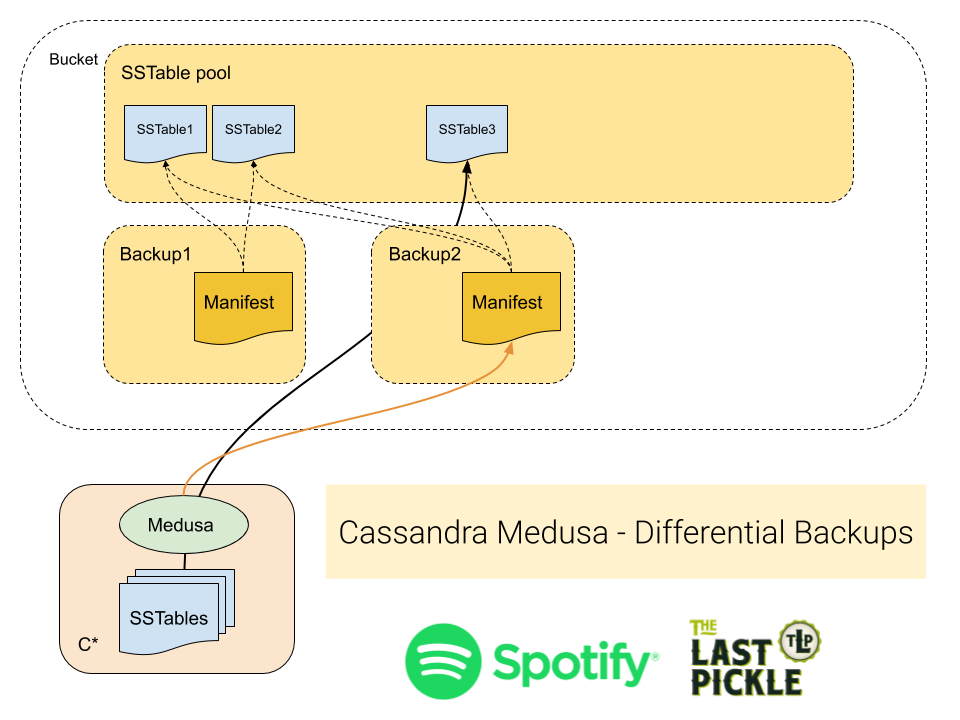
All Medusa backups only copy new SSTables from the nodes, reducing the network traffic needed. It then has two ways of managing the files in the backup catalog that we call Full or Differential backups. For Differential backups only references to SSTables are kept by each new backup, so that only a single instance of each SStable exists no matter how many backups it is in. Differential backups are the default and in operations at Spotify reduced the backup size for some clusters by up to 80%.
Full backups create a complete copy of all SSTables on the node each time they run. Files that have not changed since the last backup will be copied in the backup catalog into the new backup (and not copied off the node). In contrast to the differential method which only creates a reference to files. Full backups are useful when you need to take a complete copy and have all the files in a single location.
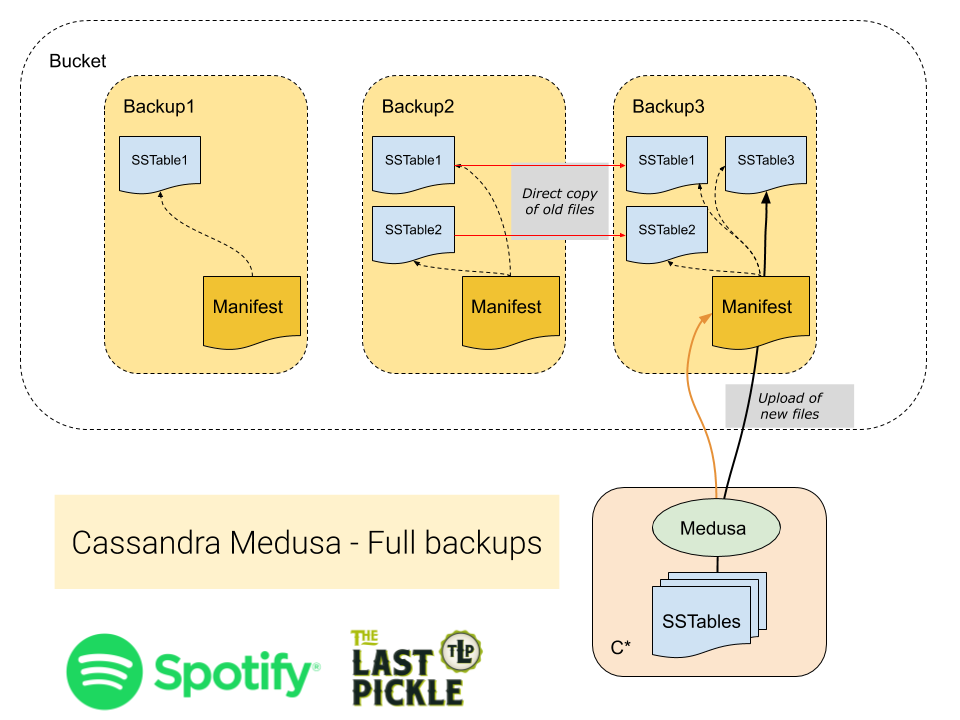
Differential backups take advantage of the immutable SSTables created by the Log Structured Merge Tree storage engine used by Cassanda. In this mode Medusa checks if the SSTable has previously being backed up, and only copies the new files (just like always). However all SSTables for the node are then stored in a single common folder, and the backup manifest contains only metadata files and references to the SSTables.
Backup A Cluster With Medusa
Medusa currently lacks an orchestration layer to run a backup on all nodes for you. In practice we have been using crontab to do cluster wide backups. While we consider the best way to automate this (and ask for suggestions) we recommend using techniques such as:
Listing Backups
All backups with the same “backup name” are considered part of the same backup for a cluster. Medusa can provide a list of all the backups for a cluster, when they started and finished, and if all the nodes have completed the backup.
To list all existing backups for a cluster, run the following command on one of the nodes:
$ medusa list-backups
2019080507 (started: 2019-08-05 07:07:03, finished: 2019-08-05 08:01:04)
2019080607 (started: 2019-08-06 07:07:04, finished: 2019-08-06 07:59:08)
2019080707 (started: 2019-08-07 07:07:04, finished: 2019-08-07 07:59:55)
2019080807 (started: 2019-08-08 07:07:03, finished: 2019-08-08 07:59:22)
2019080907 (started: 2019-08-09 07:07:04, finished: 2019-08-09 08:00:14)
2019081007 (started: 2019-08-10 07:07:04, finished: 2019-08-10 08:02:41)
2019081107 (started: 2019-08-11 07:07:04, finished: 2019-08-11 08:03:48)
2019081207 (started: 2019-08-12 07:07:04, finished: 2019-08-12 07:59:59)
2019081307 (started: 2019-08-13 07:07:03, finished: Incomplete [179 of 180 nodes])
2019081407 (started: 2019-08-14 07:07:04, finished: 2019-08-14 07:56:44)
2019081507 (started: 2019-08-15 07:07:03, finished: 2019-08-15 07:50:24)
In the example above the backup called “2019081307” is marked as incomplete because 1 of the 180 nodes failed to complete a backup with that name.
It is also possible to verify that all expected files are present for a backup, and their content matches hashes generated at the time of the backup. All these operations and more are detailed in the Medusa README file.
Restoring Backups
While orchestration is lacking for backups, Medusa coordinates restoring a whole cluster so you only need to run one command. The process connects to nodes via SSH, starting and stopping Cassandra as needed, until the cluster is ready for you to use. The restore process handles three different use cases.
- Restore to the same cluster.
- Restore to a different cluster with the same number of nodes.
- Restore to a different cluster with a different number of nodes.
Case #1 - Restore To The Same Cluster
This is the simplest case: restoring a backup to the same cluster. The topology of the cluster has not changed and all the nodes that were present at the time the backup was created are still running in the cluster.
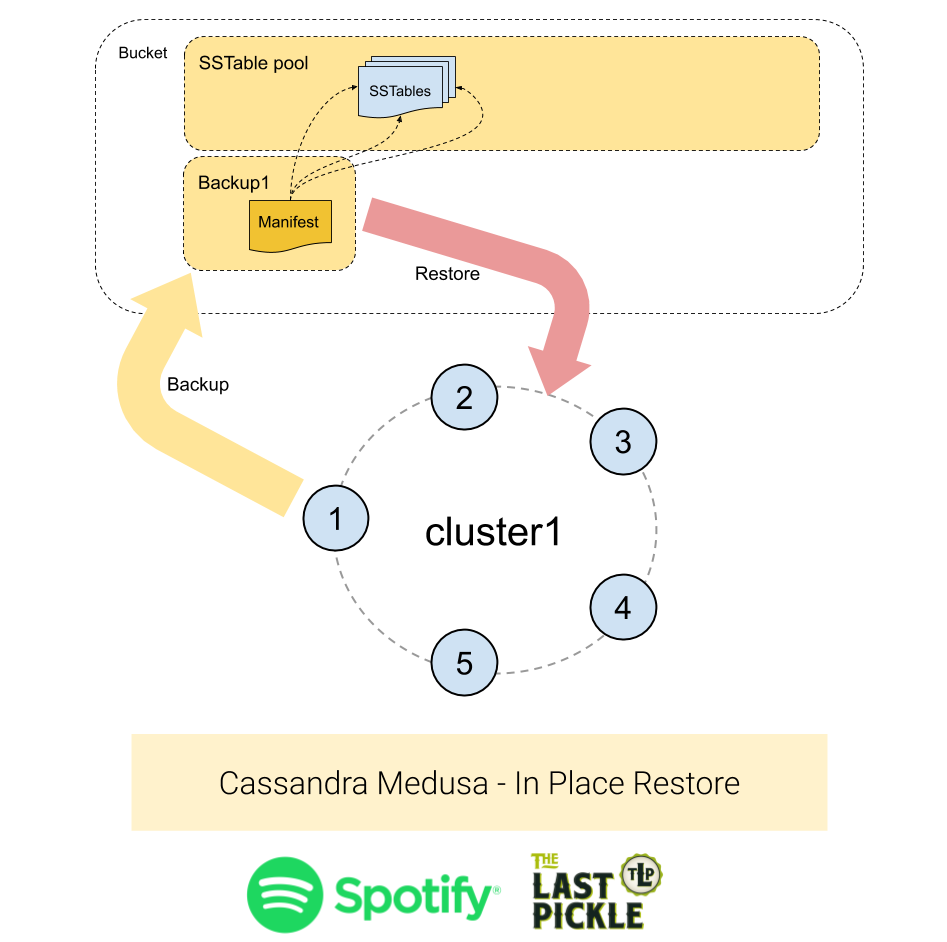
Use the following command to run an in-place restore:
$ medusa restore-cluster --backup-name=<name of the backup> \
--seed-target node1.domain.net
The seed target node will be used as a contact point to discover the other nodes in the cluster. Medusa will discover the number of nodes and token assignments in the cluster and check that it matches the topology of the source cluster.
To complete this restore each node will:
- Download the backup data into the
/tmpdirectory. - Stop Cassandra.
- Delete the commit log, saved caches and data directory including system keyspaces.
- Move the downloaded SSTables into to the data directory.
- Start Cassandra.
The schema does not need to be recreated as it is contained in the system keyspace, and copied from the backup.
Case #2 - Restore To A Different Cluster With Same Number Of Nodes
Restoring to a different cluster with the same number of nodes is a little harder because:
- The destination cluster may have a different name, which is stored in system.local table.
- The nodes may have different names.
- The nodes may have different token assignments.
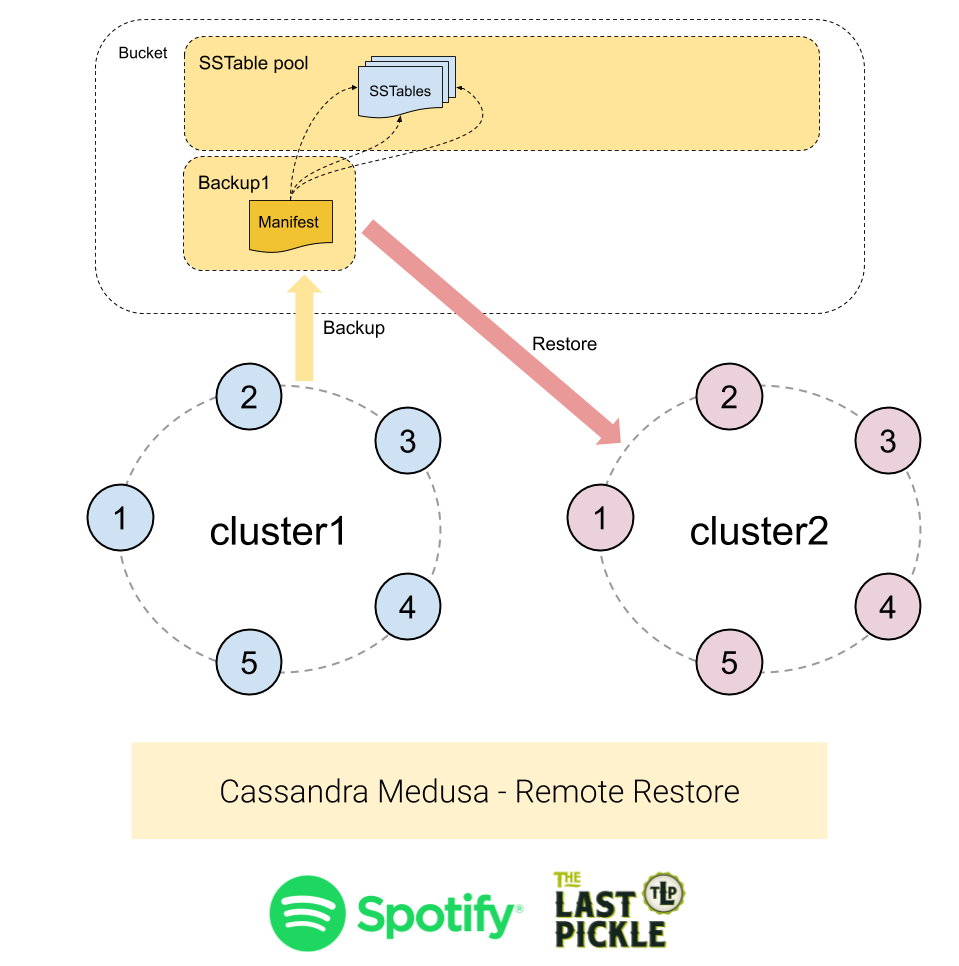
Use the following command to run a remote restore:
$ medusa restore-cluster --backup-name=<name of the backup> \
--host-list <mapping file>
The host-list parameter tells Medusa how to map from the original backup nodes to the destination nodes in the new cluster, which is assumed to be a working Cassandra cluster. The mapping file must be a Command Separated File (without a heading row) with the following columns:
- is_seed:
TrueorFalseindicating if the destination node is a seed node. So we can restore and start the seed nodes first. - target_node: Host name of a node in the target cluster.
- source_node: Host name of a source node to copy the backup data from.
For example:
True,new_node1.foo.net,old_node1.foo.net
True,new_node2.foo.net,old_node2.foo.net
False,new_node3.foo.net,old_node3.foo.net
In addition to the steps listed for Case 1 above, when performing a backup to a remote cluster the following steps are taken:
- The system.local and system.peers tables are not modified to preserve the cluster name and prevent the target cluster from connecting to the source cluster.
- The system_auth keyspace is restored from the backup, unless the
--keep-authflag is passed to the restore command. - Token ownership is updated on the target nodes to match the source nodes by passing the
-Dcassandra.initial_tokenJVM parameter when the node is restarted. Which causes ownership to be updated in the local system keyspace.
Case #3 - Restore To A Different Cluster With A Different Number Of Nodes
Restoring to a different cluster with a different number of nodes is the hardest case to deal with because:
- The destination cluster may have a different name, which is stored in system.local table.
- The nodes may have different names.
- The nodes may have different token assignments.
- Token ranges can never be the same as there is a different number of nodes.
The last point is the crux of the matter. We cannot get the same token assignments because we have a different number of nodes, and the tokens are assigned to evenly distribute the data between nodes. However the SSTables we have backed up contain data aligned to the token ranges defined in the source cluster. The restore process must ensure the data is placed on the nodes which are replicas according to the new token assignments, or data will appear to have been lost.
To support restoring data into a different topology Medusa uses the sstableloader tool from the Cassandra code base. While slower than copying the files from the backup the sstableloader is able to “repair” data into the destination cluster. It does this by reading the token assignments and streaming the parts of the SSTable that match the new tokens ranges to all the replicas in the cluster.
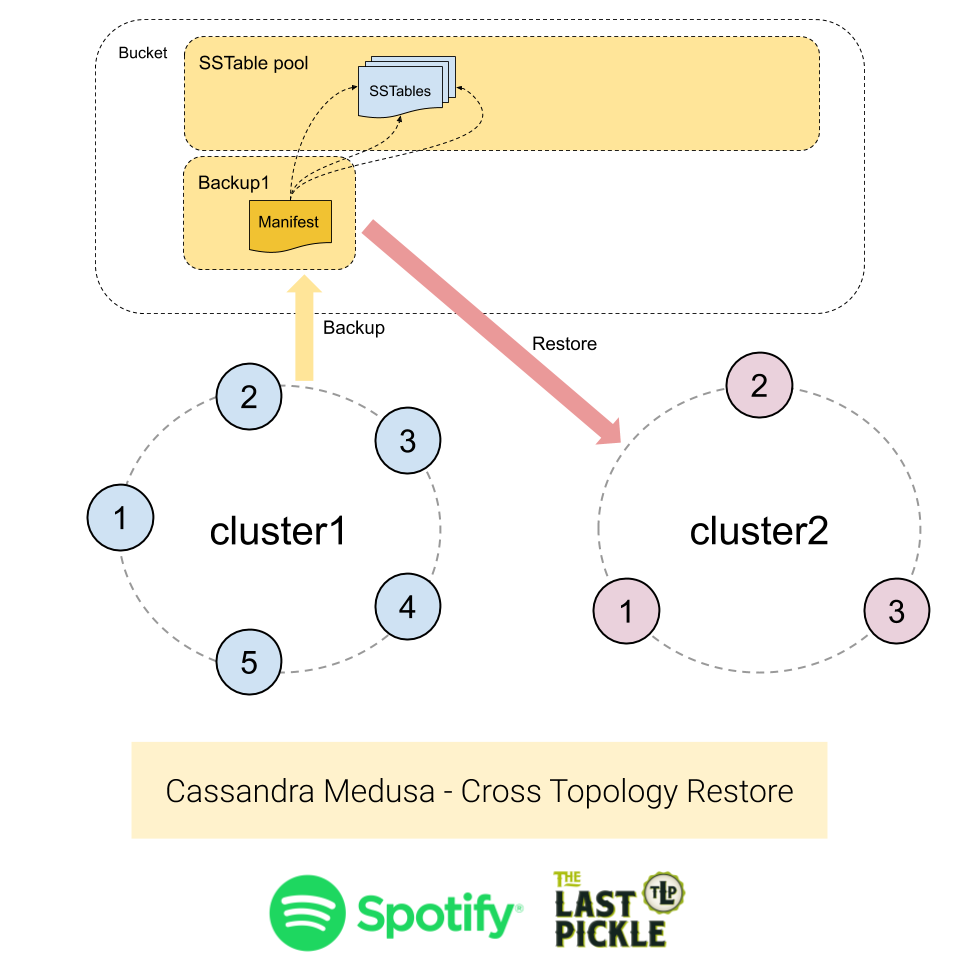
Use the following command to run a restore to a cluster with a different topology :
$ medusa restore-cluster --backup-name=<name of the backup> \
--seed-target target_node1.domain.net
Restoring data using this technique has some drawbacks:
- The restore will take significantly longer.
- The amount of data loaded into the cluster will be the size of the backup set multiplied by the Replication Factor. For example, a backup of a cluster with Replication Factor 3 will have 9 copies of the data loaded into it. The extra replicas will be removed by compaction however the total on disk load during the restore process will be higher than what it will be at the end of the restore. See below for a further discussion.
- The current schema in the cluster will be dropped and a new one created using the schema from the backup. By default Cassandra will take a snapshot when the schema is dropped, a feature controlled by the
auto_snapshotconfiguration setting, which will not be cleared up by Medusa or Cassandra. If there is an existing schema with data it will take extra disk space. This is a sane safety precaution, and a simple work around is to manually ensure the destination cluster does not have any data in it.
A few extra words on the amplification of data when restoring using sstableloader. The backup has the replicated data and lets say we have a Replication Factor of 3, roughly speaking there are 3 copies of each partition. Those copies are spread around the SSTables we collected from each node. As we process each SSTable the sstableloader repairs the data back into the cluster, sending it to the 3 new replicas. So the backup contains 3 copies, we process each copy, and we send each copy to the 3 new replicas, which means in this case:
- The restore sends nine copies of data to the cluster.
- Each node gets three copies of data rather than one.
The following sequence of operations will happen when running this type of restore:
- Drop the schema objects and re-create them (once for the whole cluster)
- Download the backup data into the /tmp directory
- Run the sstableloader for each of the tables in the backup
Available Now On GitHub
Medusa is now available on GitHub and is available through PyPi. With this blog post and the readme file in the repository you should be able to take a backup within minutes of getting started. As always if you have any problems create an issue in the GitHub project to get some help. It has been in use for several months at Spotify, storing petabytes of backups in Google Cloud Storage (GCS), and we thank Spotify for donating the software to the community to allow others to have the same confidence that their data is safely backed up.
One last thing, contributions are happily accepted especially to add support for new object storage providers.