![]()
Mick Semb Wever
Apache Cassandra's Continuous Integration Systems
With Apache Cassandra 4.0 just around the corner, and the feature freeze on trunk lifted, let’s take a dive into the efforts ongoing with the project’s testing and Continuous Integration systems.
continuous integration in open source
Every software project benefits from sound testing practices and having a continuous integration in place. Even more so for open source projects. From contributors working around the world in many different timezones, particularly prone to broken builds and longer wait times and uncertainties, to contributors just not having the same communication bandwidths between each other because they work in different companies and are scratching different itches.
This is especially true for Apache Cassandra. As an early-maturity technology used everywhere on mission critical data, stability and reliability are crucial for deployments. Contributors from many companies: Alibaba, Amazon, Apple, Bloomberg, Dynatrace, DataStax, Huawei, Instaclustr, Netflix, Pythian, and more; need to coordinate and collaborate and most importantly trust each other.
During the feature freeze the project was fortunate to not just stabilise and fix tons of tests, but to also expand its continuous integration systems. This really helps set the stage for a post 4.0 roadmap that features heavy on pluggability, developer experience and safety, as well as aiming for an always-shippable trunk.
@ cassandra
The continuous integration systems at play are CircleCI and ci-cassandra.apache.org
CircleCI is a commercial solution. The main usage today of CircleCI is pre-commit, that is testing your patches while they get reviewed before they get merged. To effectively use CircleCI on Cassandra requires either the medium or high resource profiles that enables the use of hundreds of containers and lots of resources, and that’s basically only available for folk working in companies that are paying for a premium CircleCI account. There are lots stages to the CircleCI pipeline, and developers just trigger those stages they feel are relevant to test that patch on.
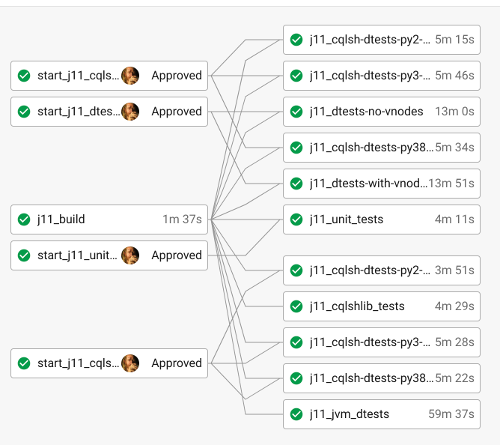
ci-cassandra is our community CI. It is based on CloudBees, provided by the ASF and running 40 agents (servers) around the world donated by numerous different companies in our community. Its main usage is post-commit, and its pipelines run every stage automatically. Today the pipeline consists of 40K tests. And for the first time in many years, on the lead up to 4.0, pipeline runs are completely green.
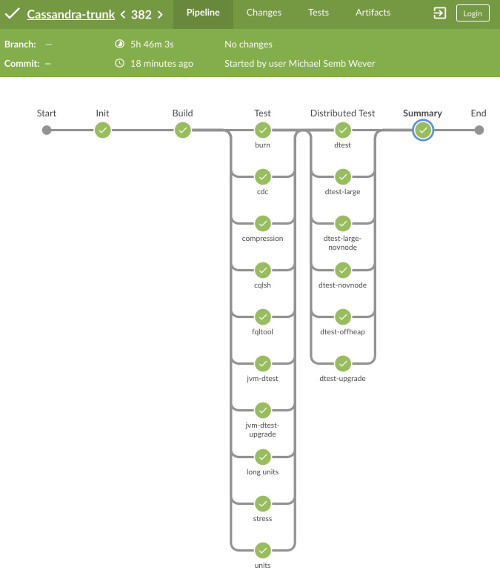
ci-cassandra is setup with a combination of Jenkins DSL script, and declarative Jenkinsfiles. These jobs use the build scripts found here.
forty thousand tests
The project has many types of tests. It has proper unit tests, and unit tests that have some embedded Cassandra server. The unit tests are run in a number of different parameterisations: from different Cassandra configuration, JDK 8 and JDK 11, to supporting the ARM architecture. There’s CQLSH tests written in Python against a single ccm node. Then there’s the Java distributed tests and Python distributed tests. The Python distributed tests are older, use CCM, and also run parameterised. The Java distributed tests are a recent addition and run the Cassandra nodes inside the JVM. Both types of distributed tests also include testing the upgrade paths of different Cassandra versions. Most new distributed tests today are written as Java distributed tests. There are also burn and microbench (JMH) tests.
distributed is difficult
Testing distributed tech is hardcore. Anyone who’s tried to run the Python upgrade dtests locally knows the pain. Running the tests in Docker helps a lot, and this is what CircleCI and ci-cassandra predominantly does. The base Docker images are found here. Distributed tests can fall over for numerous reasons, exacerbated in ci-cassandra with heterogenous servers around the world and all the possible network and disk issues that can occur. Just for the 4.0 release over 200 Jira tickets were focused just on strengthening flakey tests. Because ci-cassandra has limited storage, the logs and test results to all runs are archived in nightlies.apache.org/cassandra.
call for help
There’s still heaps to do. This is all part-time and volunteer efforts. No one in the community is dedicated to these systems or as a build engineer. The project can use all the help it can get.
There’s a ton of exciting stuff to add. Some examples are microbench and JMH reports, Jacoco test coverage reports, Harry for fuzz testing, Adelphi or Fallout for end-to-end performance and comparison testing, hooking up Apache Yetus for efficient resource usage, or putting our Jenkins stack into a k8s operator run script so you can run the pipeline on your own k8s cluster.
So don’t be afraid to jump in, pick your poison, we’d love to see you!