![]()
Alex Dejanovski
Reaper 0.6.1 released
Since we created our hard fork of Spotify’s great repair tool, Reaper, we’ve been committed to make it the “de facto” community tool to manage repairing Apache Cassandra clusters.
This required Reaper to support all versions of Apache Cassandra (starting from 1.2) and some features it lacked like incremental repair.
Another thing we really wanted to bring in was to remove the dependency on a Postgres database to store Reaper data. As Apache Cassandra users, it felt natural to store these in our favorite database.
Reaper 0.6.1
We are happy to announce the release of Reaper 0.6.1.
Apache Cassandra as a backend storage for Reaper was introduced in 0.4.0, but it appeared that it was creating a high load on the cluster hosting its data.
While the Postgres backend could rely on indexes to search efficiently for segments to process, the C* backend had to scan all segments and filter afterwards. The initial data model didn’t account for the frequency of those scans, which generated a lot of requests per seconds once you had repairs with hundreds (if not thousands) of segments.
Then it seems, Reaper was designed to work on clusters that do not use vnodes. Computing the number of possible parallel segment repairs for a job used the number of tokens divided by the replication factor, instead of using the number of nodes divided by the replication factor.
This lead to create a lot of overhead with threads trying and failing to repair segments because the nodes were already involved in a repair operation, each attempt generating a full scan of all segments.
Both issues are fixed in Reaper 0.6.1 with a brand new data model which requires a single query to get all segments for a run, the use of timeuuids instead of long ids in order to avoid lightweight transactions when generating repair/segment ids and a fixed computation of the number of possible parallel repairs.
The following graph shows the differences before and after the fix, observed on a 3 nodes cluster using 32 vnodes :
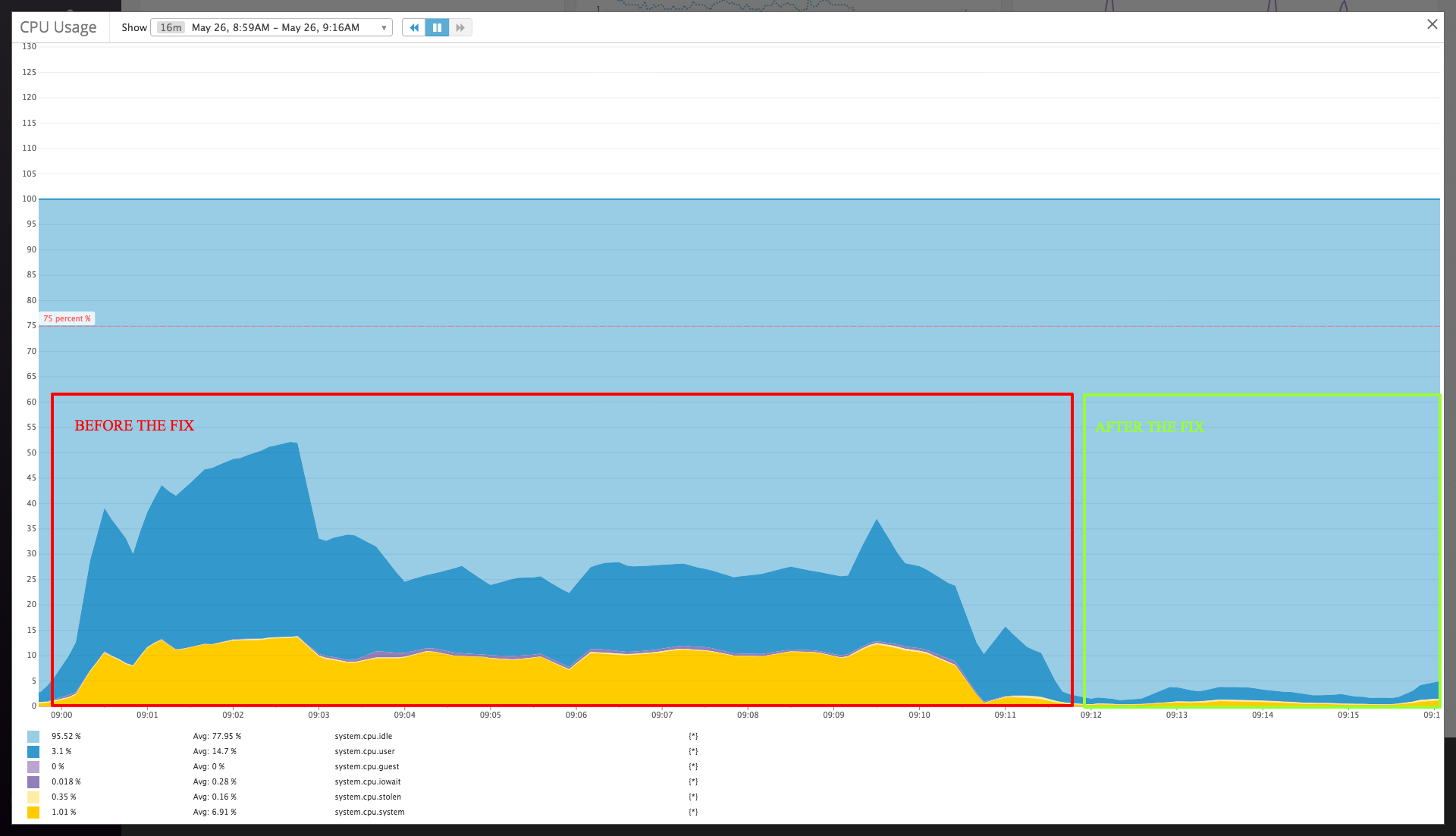
The load on the nodes is now comparable to running Reaper with the memory backend :
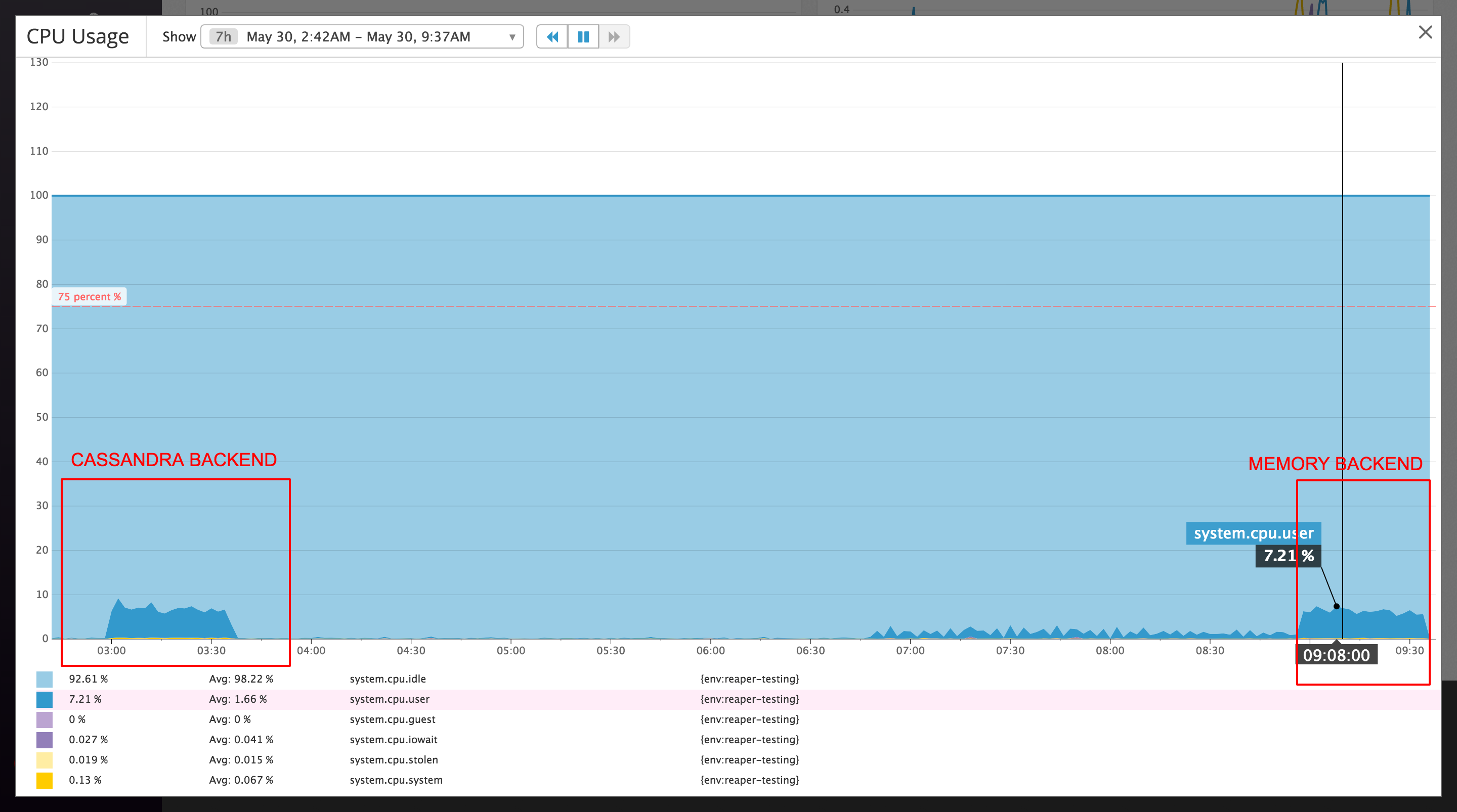
This release makes Apache Cassandra a first class citizen as a Reaper backend!
Upcoming features with the Apache Cassandra backend
On top of not having to administer yet another kind of database on top of Apache Cassandra to run Reaper, we can now better integrate with multi region clusters and handle security concerns related to JMX access.
First, the Apache Cassandra backend allows us to start several instances of Reaper instead of one, bringing it fault tolerance. Instances will share the work on segments using lightweight transactions and metrics will be stored in the database. On multi region clusters, where the JMX port is closed in cross DC communications, it will give the opportunity to start one or more instances of Reaper in each region. They will coordinate together through the backend and Reaper will still be able to apply backpressure mechanisms, by monitoring the whole cluster for running repairs and pending compactions.
Next, comes the “local mode”, for companies that apply strict security policies for the JMX port and forbid all remote access.
In this specific case, a new parameter was added in the configuration yaml file to activate the local mode and you will need to start one instance of Reaper on each C* node. Each instance will then only communicate with the local node on 127.0.0.1 and ignore all tokens for which this node isn’t a replica.
Those feature are both available in a feature branch that will be merged before the next release.
While the fault tolerant features have been tested in different scenarios and considered ready for use, the local mode still needs a little bit of work before usage on real clusters.
Improving the frontend too
So far, we hadn’t touched the frontend and focused on the backend.
Now we are giving some love to the UI as well. On top of making it more usable and good looking, we are pushing some new features that will make Reaper “not just a tool for managing repairs”.
The first significant addition is the new cluster health view on the home screen :
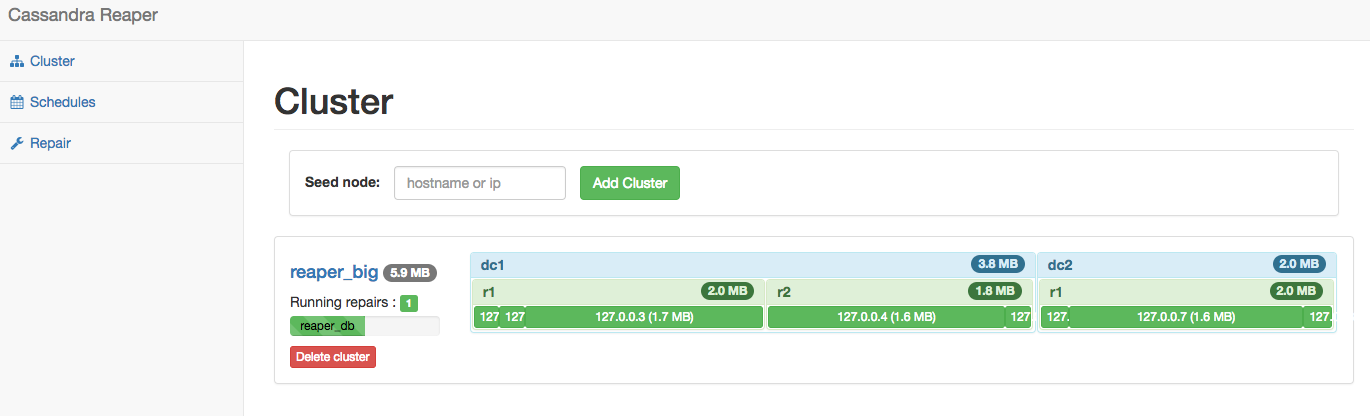
One quick look at this screen will give you the nodes individual status (up/down) and the size on disk for each node, rack and datacenter of the clusters Reaper is connected to.
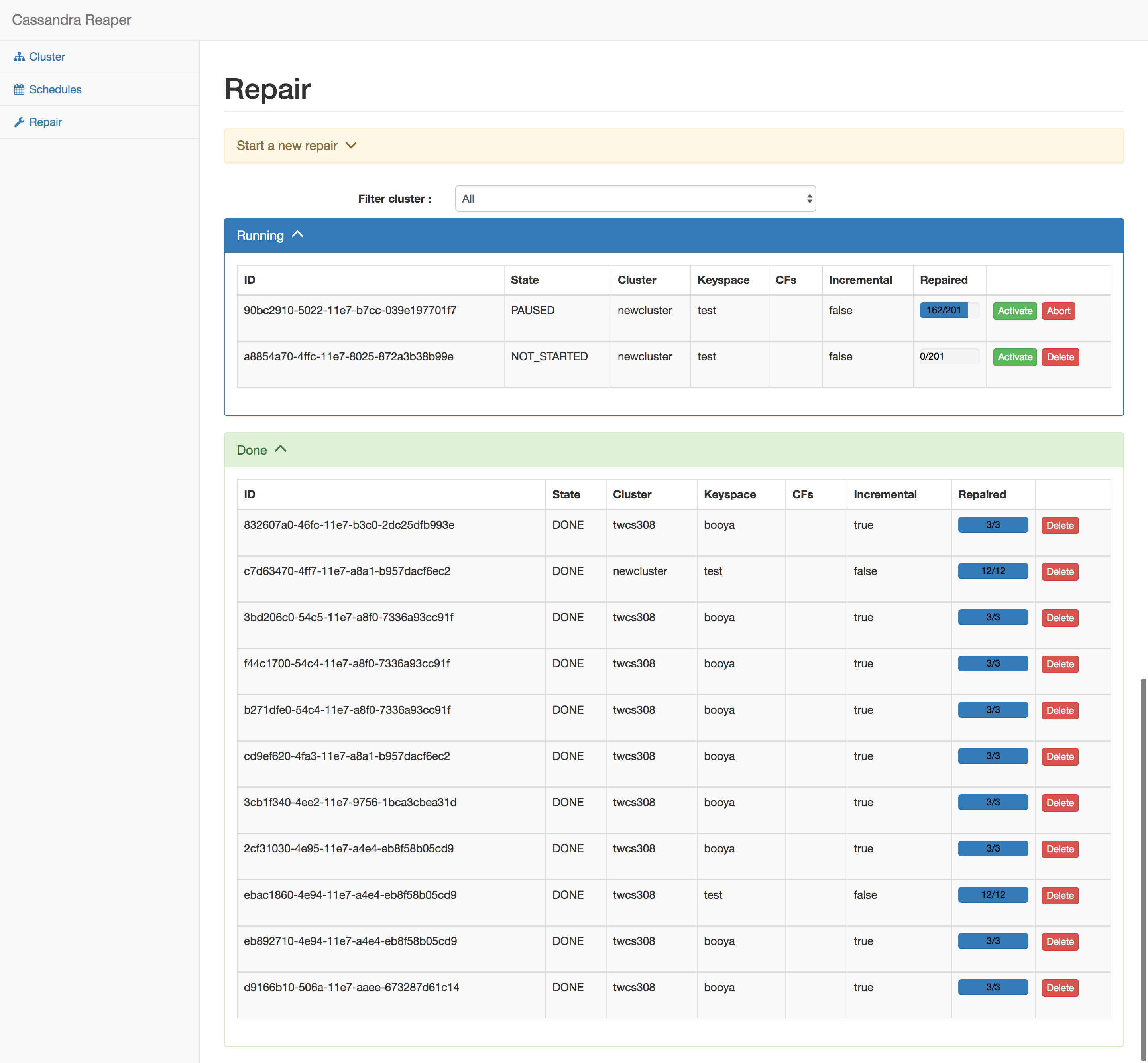
Then we’ve reorganized the other screens, making forms and lists collapsible, and adding a bit of color :
All those UI changes were just merged into master for your testing pleasure, so feel free to build, deploy and be sure to give us feedback on the reaper mailing list!