![]()
Aaron Morton
Introduction To The Apache Cassandra 3.x Storage Engine
Have you ever relived a past experience and found it better the second time round? For example I used to love Monkey Magic when I was a child, but am not such a big fan now. When oh when will Pigsy change his piggish ways? The first time I got to see how a Database actually worked was in 2010 when I started playing with Apache Cassandra. It was a revelation after years of using platforms such as Microsoft SQL Server, and I decided to make a career out of working with Cassandra. It’s now 2016 and the Cassandra storage engine recently went through some big changes with the release of 3.x. Once again I have a chance to dive into the storage engine, and this time it is even more enjoyable as I have been able to see how the project has improved. Which has resulted in this post on how the 3.x storage engine ecodes Partitions on disk.
It’s The Disk Stupid
Databases, or to be precise databases that can scale, are all about how to get bytes on and off disk. The team responsible for the 3.x storage engine have done an amazing job making it easier for Cassandra to get bytes off disk. I’ll try to take a look at that soon, for now I am going to look at how data is laid out on disk.
The first step in understanding the 3.x storage engine is to accept the new mental model. Those that knew the Thrift API prior to Cassandra 3.0 basically knew how the storage engine worked; each internal row was an ordered list of columns that optionally had a value. This was kind of fun to start with, then we started having more complicated use cases which lead to some common abstractions. These abstractions were formalised in CQL 3, which gave birth to terms such as Partition and Clustering that while they have become the lingua franca for Cassandra were not natively supported by the previous storage engine.
Starting with the 3.x storage engine Partitions, Rows, and Clustering are natively supported. A Partition is a collection of Rows that share the same Partition Key(s) that are ordered, within the Partition, by their Clustering Key(s). Rows are then by globally identified by their Primary Key: the combination of Partition Key and Clustering Key. The important change is that the 3.x storage engine now knows about these ideas, it may seem strange but previously it did not know about the Rows in a Partition. The new storage engine was created specifically to handle these concepts in a way that reduces storage requirements and improves performance.
Just The Data
Serialising to the -Data.db component of the SSTable starts with the Partition. When we decide to flush a Memtable to disk a call to Memtable.FlushRunnable.writeSortedContents() is made, this iterates the Partitions in the Memtable making a call for each that ends up at BigTableWriter.append(). As we are focusing on Partitions we will be looking at what happens when ColumnIndex.writeAndBuildIndex() is called.
At a broad level the layout of a Partition in the -Data.db file has three components: A header, following by zero or one static Rows, followed by zero or more Clusterable objects.

Clusterable objects are simply Objects that can be ordered by a ClusteringPrefix. Generally that means something that extends Unfiltered, which has a handy Kind enum with two values: ROW or RANGE_TOMBSTONE_MARKER. Which means on disk a Partition consists of a header, followed by 1 or more Unfiltered objects.
Partition Header
The partition header has a simple layout, containing the Partition Key and deletion information.

Breaking this down:
- The Partition Key is the concatenated Columns of the Partition Key defined in your Table.
- The length of the Partition Key is encoded using a short, giving it a max length of 65,535 bytes.
- The concatenated bytes of the Partition Key columns are then written out.
- The DeletionTime for the partition contains deletion information for partition tombstones.
DeletionTime.localDeletionTimeis the server time in seconds when the deletion occurred, which is compared togc_grace_secondsto decide when it can be purged. When used with a TTL thelocalDeletionTimeis the time the data expires.DeletionTime.markedForDeleteAtis the timestamp of the deletion, data with a timestamp less than this value is considered deleted.
Row
A Row may be either static or non-static. If the Partition contains a static row it is written before the Clusterable objects. It’s important to remember that as we are flushing from the Memtable we are dealing with a fragment of the Partition. That is a summary of the recent inserts into the table; if no recent inserts wrote to the static columns the Partition in the Memtable will not contain a Static Row. As we will see below, the only difference between a static and non-static Row on disk is the presence of a ClusteringPrefix.
If you want to follow along in the code a static Row is serialized by calling UnfilteredSerializer.serializeStaticRow(), but ultimately all the work (for static and non-static Rows) is done in UnfilteredSerializer.serialize().
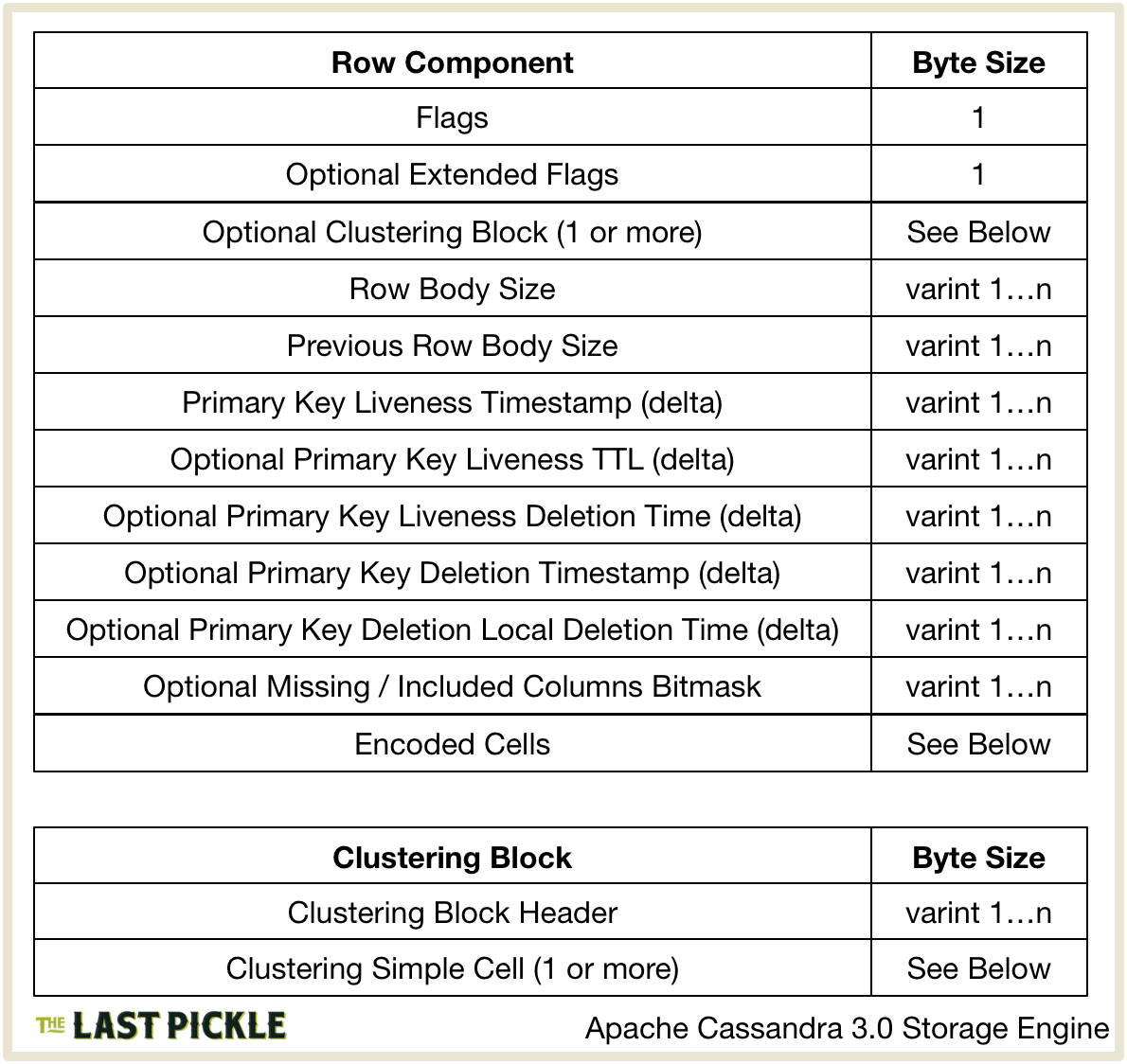
Breaking this down:
- Flags is a single byte bitmask whose values are defined at the top of the UnfilteredSerializer class.
- Extended Flags is a single byte included if the
EXTENSION_FLAGis set in the Flags. This is always set for a Static Row and is set if there is a “SHADOWABLE” deletion, let me get back to you on that one :). - For non-static rows the
CluteringPrefixis the encoded by ClusteringPrefix.seriallizeValuesWithoutSize in blocks of 32 Cells. For each 32 Cell block:- A variable integer header is calculated by ClusteringPrefix.makeHeader(). Two bits are used for each Cell in the
ClusteringPrefixto encode if the Cell value is null, empty, or otherwise. - For each Cell that is neither null or empty the value is encoded using the methods described below for a simple Cell.
- A variable integer header is calculated by ClusteringPrefix.makeHeader(). Two bits are used for each Cell in the
- The size of the row is calculated by
UnfilteredSerializer.serializedRowBodySize()and encoded as a variable sized integer using VIntCoding.writeUnsignedVInt(). If possible it will be a single byte. - Next the size of the previous row is encoded, again as a variable sized integer. My guess is this is encoded to enable reverse scanning on the data, but I’ve not looked into it yet.
- The LivenessInfo for the row is included if it is not empty. Liveness is used to determine if a row is alive yet empty or dead. The best explanation I’ve found is the comment for Row.primaryKeyLivenessInfo(). If it is not empty the delta of
LivenessInfo.timestampfrom EncodingStats.minTimestamp is stored as a variable sized integer. TheEncodingStatsare maintained by Memtable.put() to contain aggregate stats such as the minimum timestamp for all information in the Memtable. Features such as this are how the 3.x storage format keeps disk size to a minimum, as the delta can be represented using as few bytes as possible. - If an ExpiringLivenessInfo is used it will also contain TTL information. This will be set when TTL information is included as a query option for a modification statement, for example on the INSERT statement.
ExpiringLivenessInfo.ttl()is encoded as a variable sized integer delta from the EncodingStats.minTTL.ExpiringLivenessInfo.localExpirationTime()is encoded as a variable sized integer delta from the EncodingStats.minLocalDeletionTime.
Row.deletion()returns the Row level deletion information, if one has occurred DeletionTime.isLive() will returnfalse, meaning there is a Deletion and we should store it (see the comments, it kind of makes sense).DeletionTime.markedForDeleteAt()is encoded as a variable sized integer delta from EncodingStats.minTimestamp.DeletionTime.localDeletionTime()is encoded as a variable sized integer delta from the EncodingStats.minLocalDeletionTime.
- If this Row does not include all the Columns included in the Memtable (tracked by ) information about which Columns it has is then encoded. It’s important to note that we are comparing the Columns in this row to the super set of all Columns encoded in all the Rows in the Memtable, not the Columns in the Table definition. Columns.serializeSubset() encodes which Columns are missing in this Row if there are less than 64 Columns, with a more complicated system used when there are more than 64 Columns. In either case we end up with a variable sized integer.
Lastly the Cells in the row are encoded, I’ve broken this into Simple and Complex Cell encoding. Encoding for Simple Cells is handled by BufferCell.Serializer.serialise().
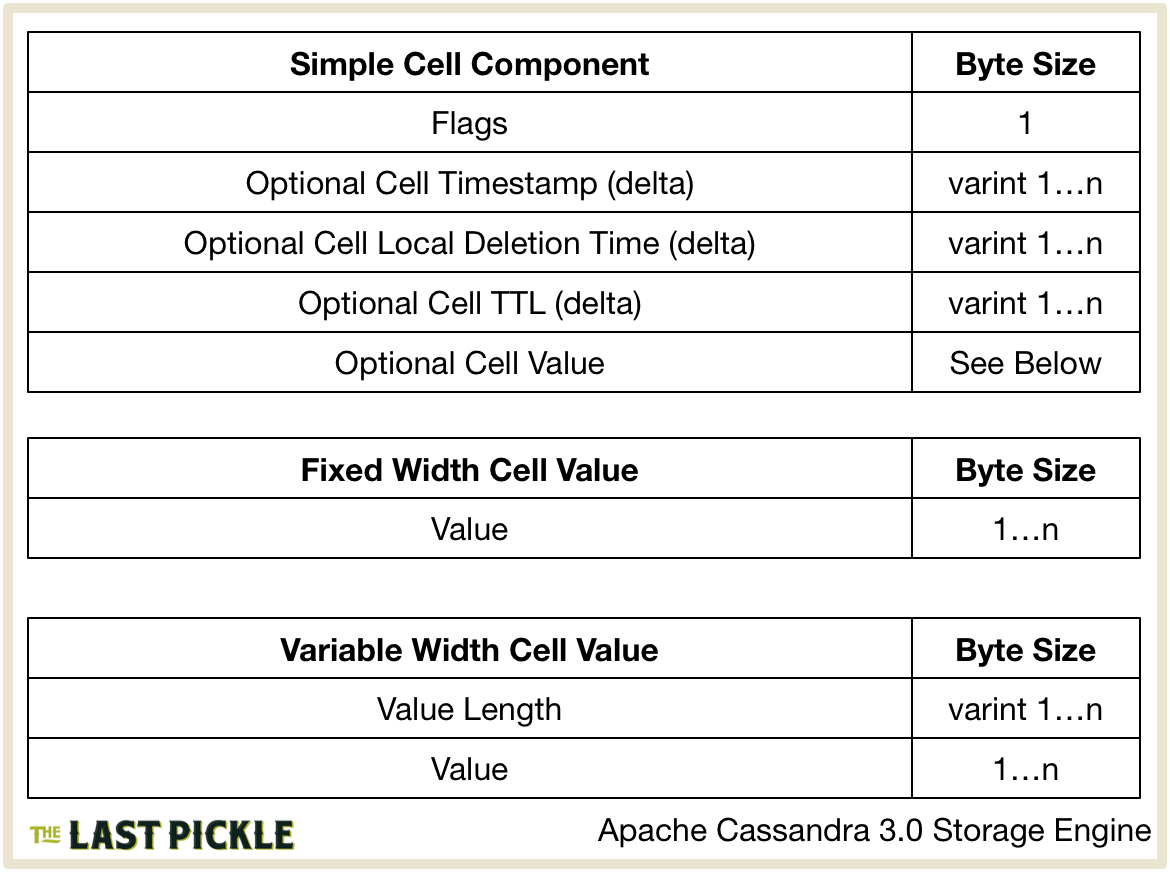
- Flags is a single byte bitmask whose values are defined in BufferCell.Serializer.
- If the Cell Timestamp is different to the Row level
LivenessInfo(see above) the timestamp is encoded as a variable sized integer delta from the EncodingStats.minTimestamp. - If the Cell is a Tombstone or an Expiring Cell and both the
localDeletionTimeandttlare different to the Row levelLivenessInfo(see above) theCell.localDeletionTime()value is encoded as a variable sized integer delta from EncodingStats.minLocalDeletionTime. - If the Cell is an Expiring Cell and both the
localDeletionTimeandttlare different to the Row levelLivenessInfo(see above) theCell.ttl()value is encoded as a variable sized integer delta from EncodingStats.minTTL. - The optional value is then encoded, fixed width data types (such as
booleanandint) simply encode the byte value while variable width types (such asblobandtext) encode both the length (as a variable sized integer) and the byte value.
ComplexColumnData are a “(non-frozen collection or UDT)” (from CellPath) and as the name suggests are more complex than Simple Cells. Encoding is handled by UnfilteredSerializer.writeComplexColumn().
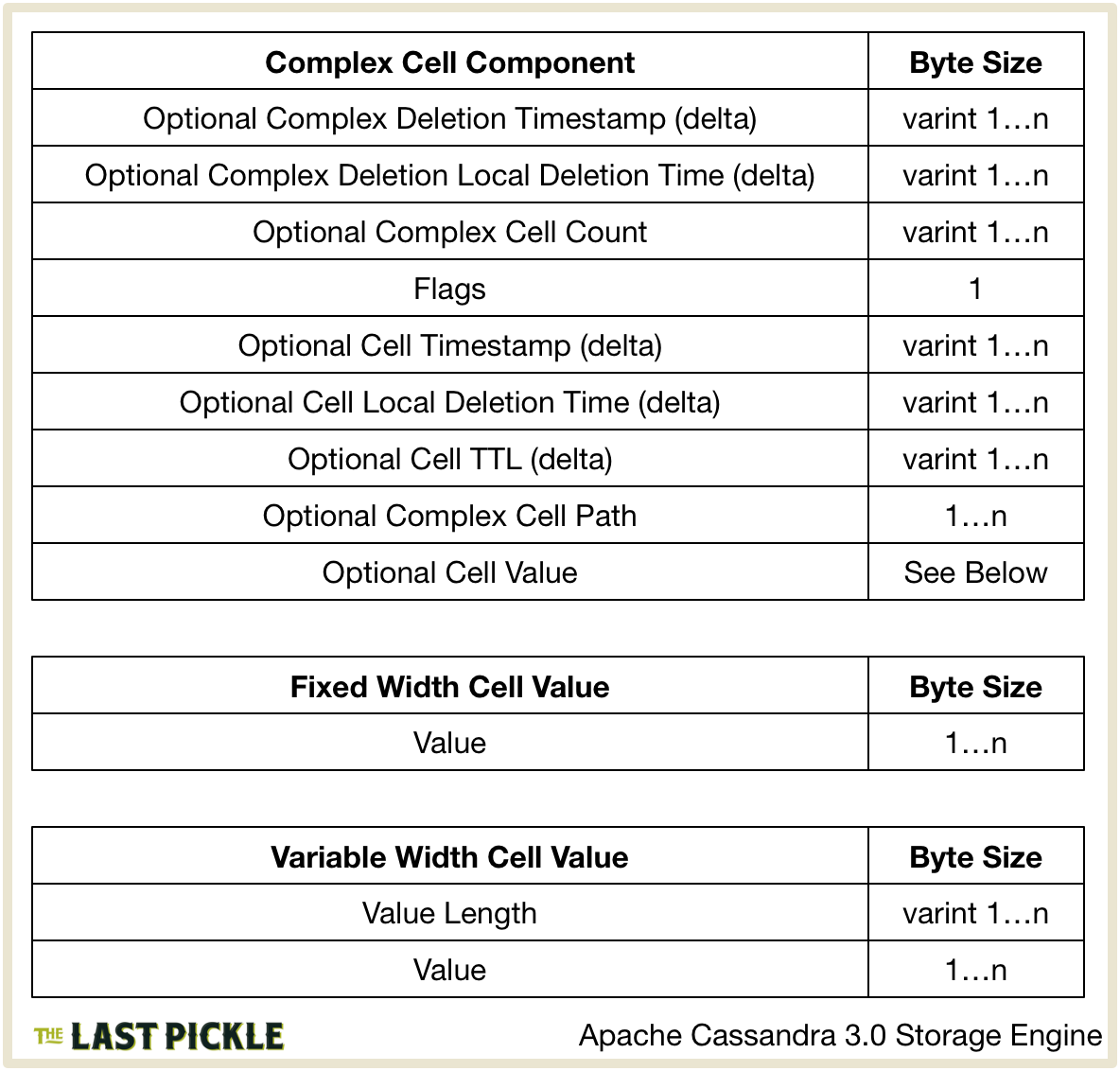
Breaking this down:
- If the Row.hasComplexDeletion() the ComplexColumnData.complexDeletion() for the Column is written first. As the comments say, this is
DeletionTimefor all the Cells in the ComplexColumnDataolumn:DeletionTime.markedForDeleteAt()is encoded as a variable sized integer delta from EncodingStats.minTimestamp.DeletionTime.localDeletionTime()is encoded as a variable sized integer delta from the EncodingStats.minLocalDeletionTime.
- The number of Cells in the Column is encoded as a variable sized integer.
- The Cells that make up the column are then encoded, much the same way as a Simple Cell with a few additions:
- The Flags, optional Cell Timestamp, optional Cell Local Deletion Time, and optional Cell TTL are encoded as above.
- The CellPath which identifies a Cell in a Complex Column, such as the key for a map, is encoded by the CellPath.Serializer for the complex type. Currently there is only one real implementation of this Interface, the CollectionType.CollectionPathSerializer. So while in theory the CellPath component is an opaque blob dependant on the Column type, in practice we know it’s a variable sized integer length followed by the
ByteBuffercontents. - The Cell value is encoded using the same process as above. In fact all Cell contents are written using AbstractType.writeValue().
Range Tombstones
Range Tombstone are used to record deletions that are removing more than a single Cell. For example when a list<> Column is overwritten all of the previous contents must be “deleted”. My treatment of them here is somewhat superficial, I will only be explaining how they are committed to disk.
The RangeTombstoneMarker is serialized by one of the UlfilteredSerializer.serialize() overloads.
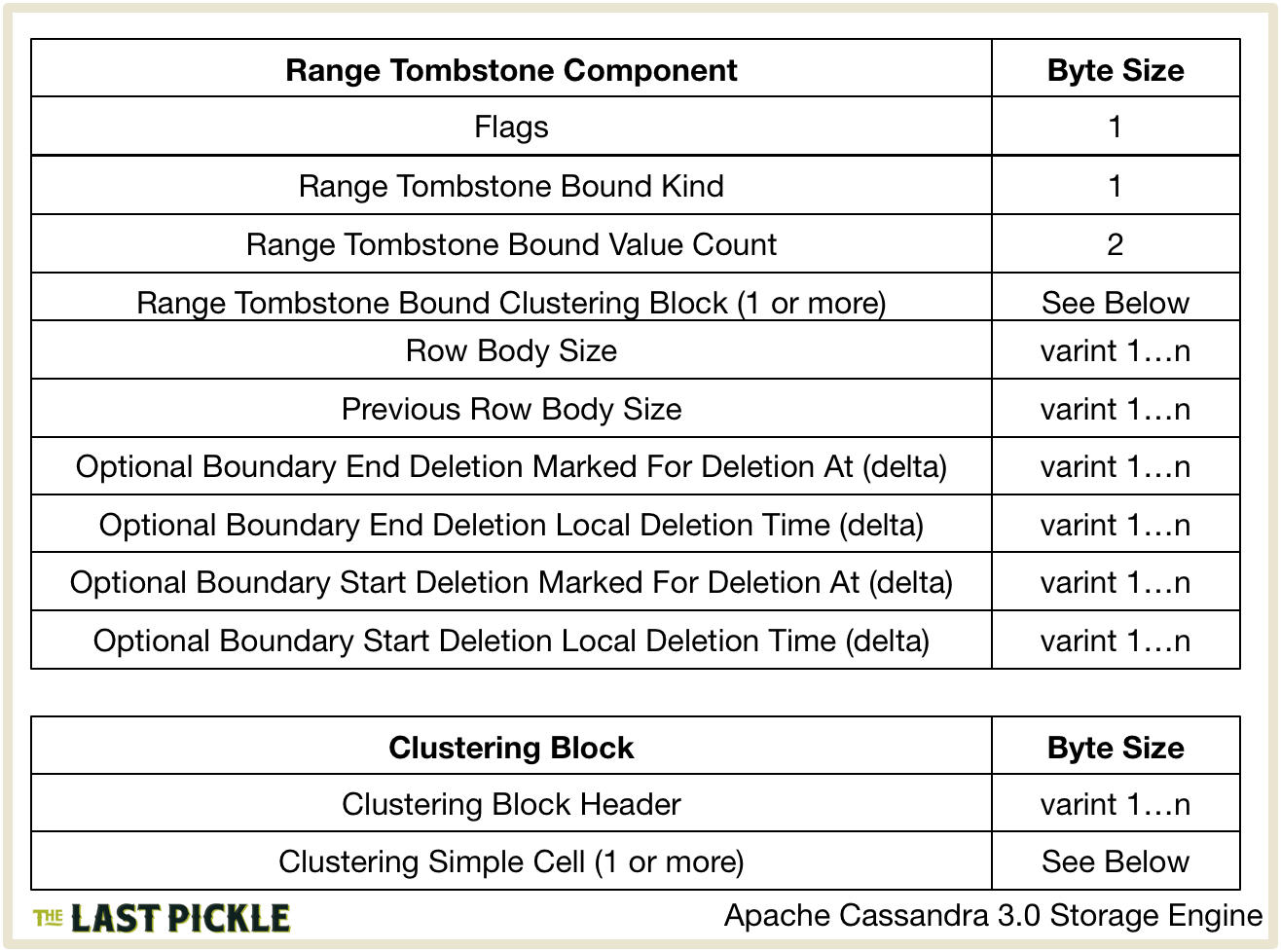
Breaking this down:
- Flags is a single byte bitmask, with the same meaning as those used for the Row, whose value is always UnfilteredSerializer.IS_MARKER.
- The clustering information for the
RangeTombstoneMarker, the RangeTombstone.Bound, is then serialised which specifies the Tombstones position in the Partition:- The ordinal value of the ClutsteringPrefix.Kind enum value for the
RangeTombstone.Boundis encoded as a single byte. This specifies how the bound should be evaluated. - The number of values in the bound, AbstractClusteringPrefix.size() is then encoded as two bytes. I’m going to guess this is either 0, 1 or 2.
- The
ClusteringPrefixprefix is then encoded in blocks using the methods described above for the Row.
- The ordinal value of the ClutsteringPrefix.Kind enum value for the
- The size of the marker is calculated by
UnfilteredSerializer.serializedMarkerBodySize()and encoded as a variable sized integer using VIntCoding.writeUnsignedVInt(). - Next the size of the previous marker or row is encoded, again as a variable sized integer.
- If the
RangeTomebstoneMarkeris a boundary marker, tested by ClusteringPrefix.kind.isBoundary(), it is cast to a RangeTombstoneBoundaryMarker and theRangeTombstoneBoundaryMarker.endDeletionTime()andRangeTombstoneBoundaryMarker.startDeletionTime()values are encoded in that order. These areDeletionTimeobjects, like the ones used in the Partition Header and Row above. For theendDeletionTime()first and then thestartDeletionTime()values:DeletionTime.markedForDeleteAt()is encoded as a variable sized integer delta from EncodingStats.minTimestamp.DeletionTime.localDeletionTime()is encoded as a variable sized integer delta from the EncodingStats.minLocalDeletionTime.
- If the
RangeTomebstoneMarkeris not a boundary marker, it is cast to a RangeTombstoneBoundMarker and the singleRangeTombstoneBoundMarker.deletionTime()is encoded:DeletionTime.markedForDeleteAt()is encoded as a variable sized integer delta from EncodingStats.minTimestamp.DeletionTime.localDeletionTime()is encoded as a variable sized integer delta from the EncodingStats.minLocalDeletionTime.
What’s Next ?
Hopefully this look at how the Partition is encoded in the -Data.db file has given you a taste of the massive changes in the 3.x storage engine. If you are new to Cassandra take a look at this 4.5 year old post about Cassandra Query Plans to see how just how far things have come.
Luckily for me there is still more to learn :)