![]()
Mick Semb Wever
Meltdown's Impact on Cassandra Latency
What impact on latency should you expect from applying the kernel patches for the Meltdown security vulnerability?
TL;DR expect a latency increase of at least 20% for both reads and writes.
History
The Meltdown vulnerability, formally CVE-2017-5754, allows rogue processes to access kernel memory. Simple demonstrations have already appeared online on how to expose passwords and ssh private keys from memory. The consequences of this, in particular on shared hosts (ie cloud) are considered “catastrophic” by security analysts. Initially discovered in early 2017, the vulnerability was planned to be publicly announced on the 9th January 2018. However, due to the attention generated by the frequency of Linux kernel ‘page-table isolation’ (KPTI) patches committed late in 2017 the news broke early on 3rd January 2018.
Impact
Without updated hardware, the Linux kernel patches impact CPU usage. While userspace programs are not directly affected, anything that triggers a lot of interrupts to the CPU, such as a database’s use of IO and network, will suffer. Early reports are showing evidence of CPU usage taking a hit between 5% and 70%. Because of the potential CPU performance hit and lack of evidence available, The Last Pickle used a little time to see what impacts we could record for ourselves.
Target
The hardware used for testing was a Lenovo X1 Carbon (gen 5) laptop. This machine runs an Intel Core i7-5600U CPU with 8Gb RAM. Running on it is Ubuntu 17.10 Artful. The unpatched kernel was version 4.13.0-21, and the patched kernel version 4.13.0-25. A physical machine was used to avoid the performance variances encountered in the different cloud environments.
The Ubuntu kernel was patched according to instructions here and the ppa:canonical-kernel-team/pti repository.
Stress
A simple schema, but typical of many Cassandra usages, was used on top of Cassandra-3.11.1 via a 3 node ccm cluster. The stress execution ran with 32 threads. Running stress, three nodes, and a large number threads on one piece of hardware was intentional so to increase thread/context switching and kernel overhead.
The stress run was limited to 5k requests per second so to avoid saturation, which occurred around 7k/s. The ratio of writes to reads was 1:1, with reads being split between whole partitions and single rows. The table used TWCS and was tuned down to 10 minute windows, so to ensure compactions ran during an otherwise short stress run. The stress ran for an hour against both the unpatched and patched kernels.
ccm stress user profile=stress.yaml ops\(insert=2,by_partition=1,by_row=1\) duration=1h -rate threads=32 throttle=5000/s -graph file=meltdown.html title=Meltdown revision=cassandra-3.11.1-unpatched
Results
The following graphs show that over every percentile a 20%+ latency increase occurs. Sometimes the increase is up around 50%.
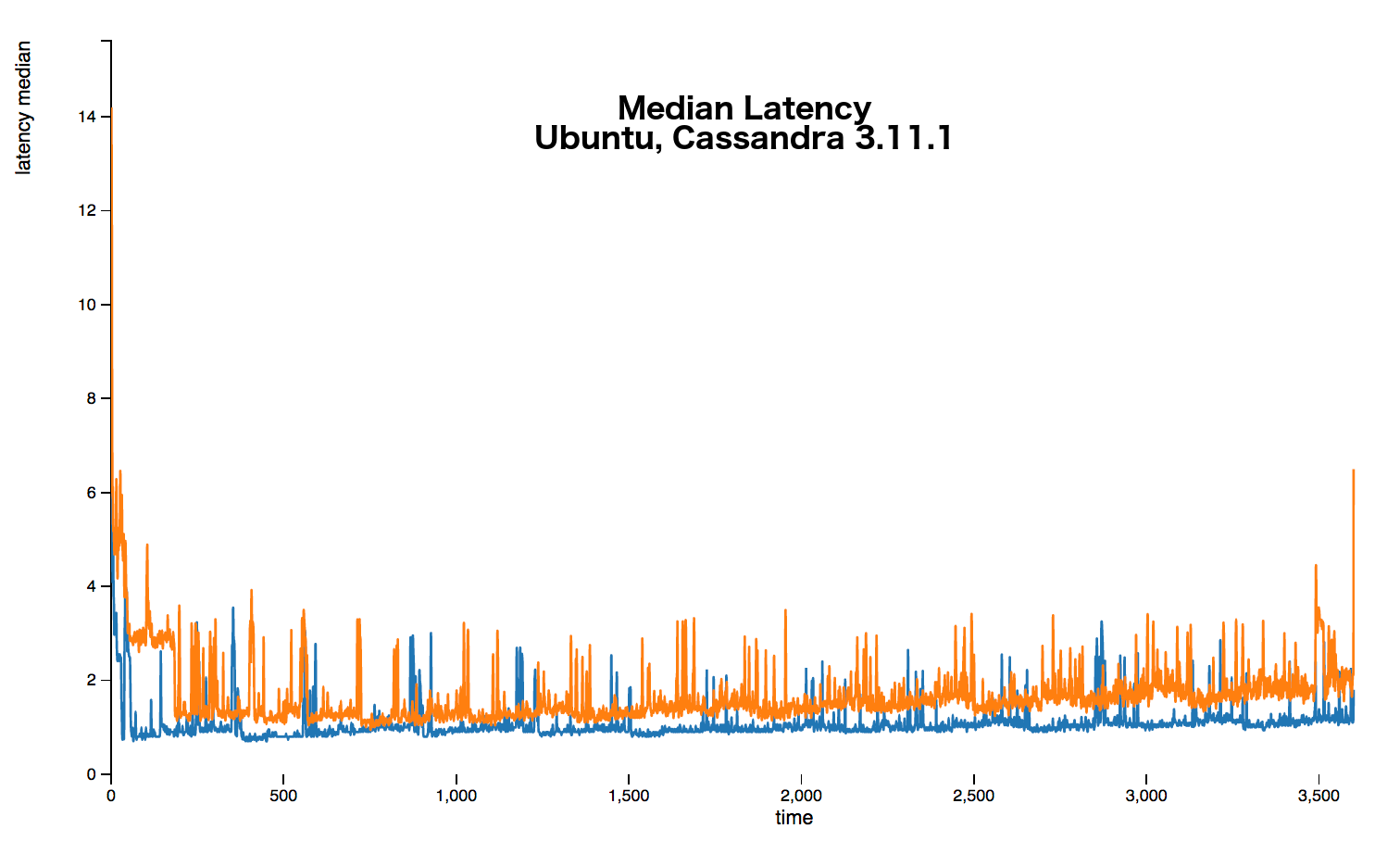
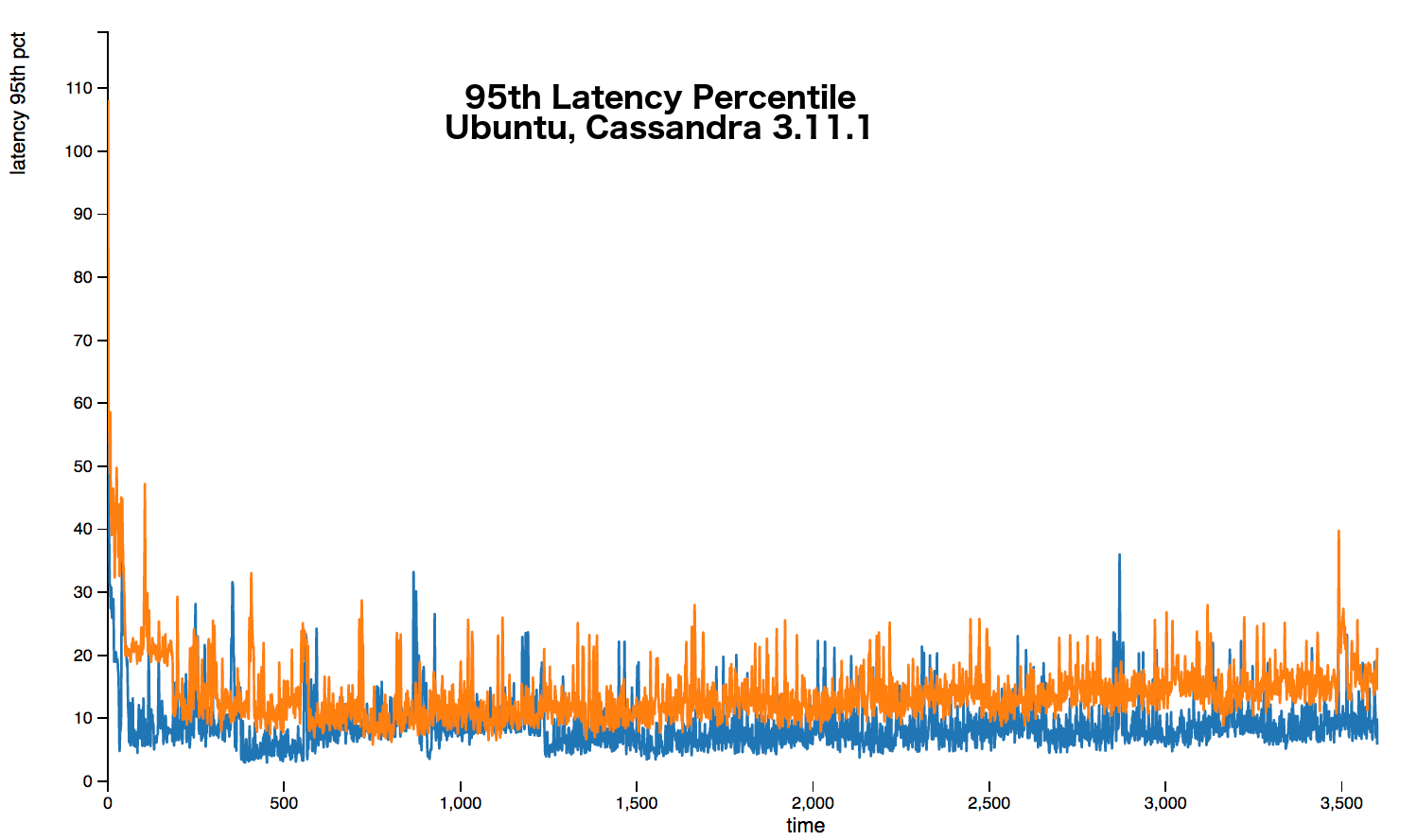
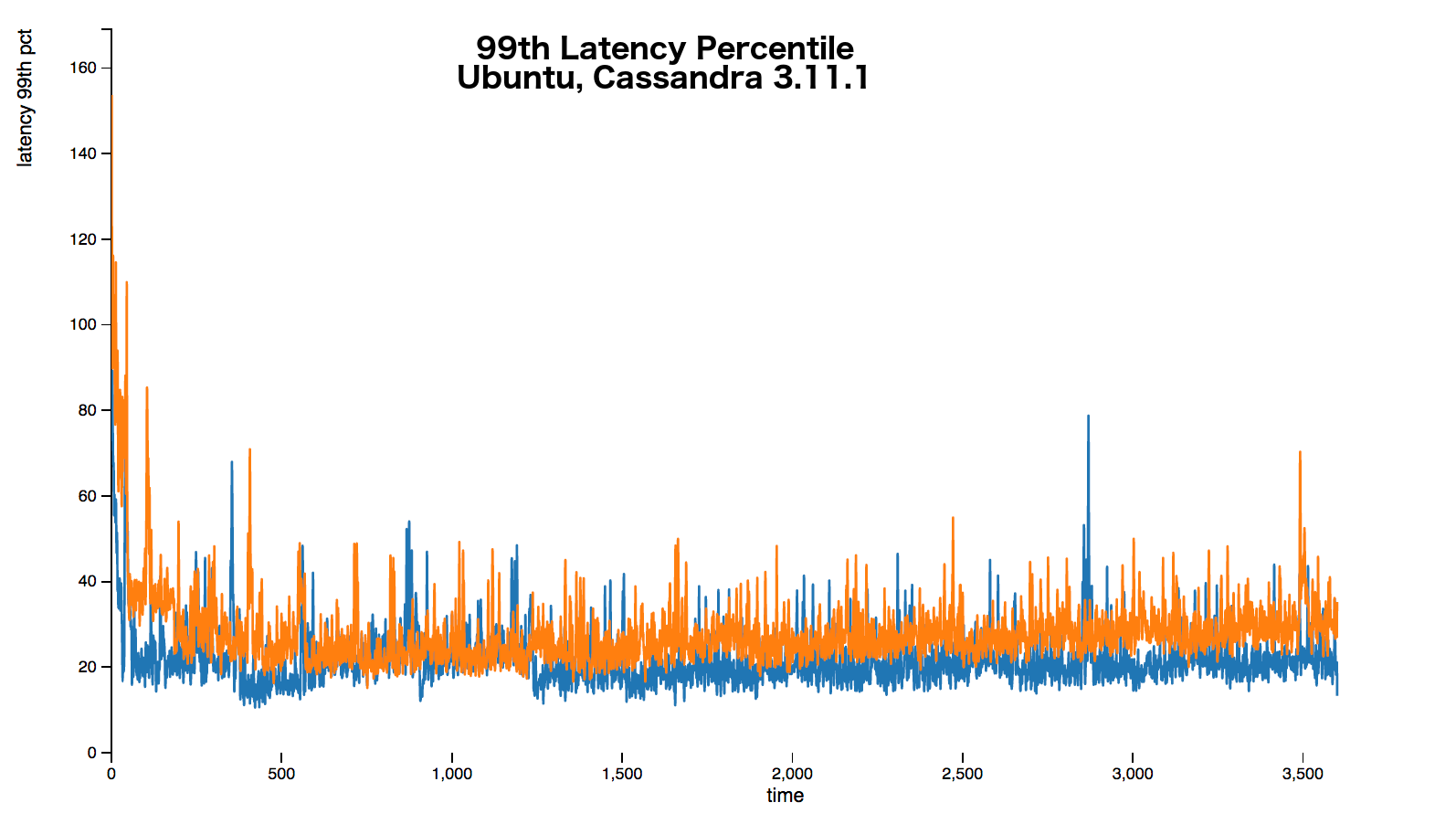
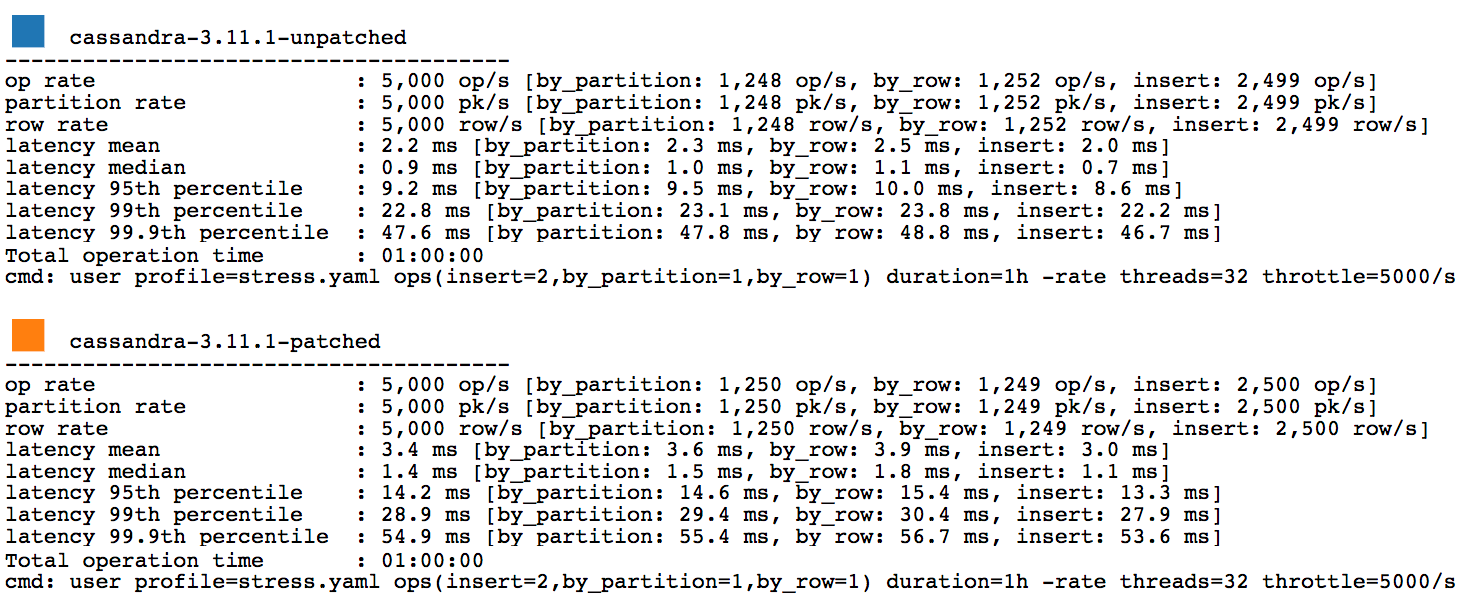
The full stress results are available here.