![]()
Alain Rodriguez
Running commands cluster-wide without any management tool
Managing Cassandra effectively often means managing multiple nodes the exact same way. As Cassandra is a peer to peer system where all the nodes are equals, there is no master or slaves. This Cassandra property allows us to easily manage any cluster by simply running the same command on all the nodes to have a change applied cluster-wide.
Yet, managing multiple nodes efficiently requires the operator to have a good set of tools. Spending some time to write scripts to automate the action the operator is about to repeat on each node will save time, removes frustration and is less error prone. Being able to operate from one node to affect all the nodes in the cluster or datacenter is also very handy. That’s why some management tools like Chef, Ansible, Salt and many more are used to manage Cassandra clusters.
In the past I faced some cases where no such tool was available, for distinct reason, like clusters being too small and where it was not worth it installing and configuring a management tool or while doing consulting and not having the management tool configured for my user. I imagine there are a lot of people managing Cassandra clusters without such a tool.
So I will expose solutions I ended up using here, to make them available to anyone in the same situation.
Small number of nodes / Using an interface
I have used csshx for a long time, managing clusters from 3 to 40 nodes in size. Basically csshx allows you to connect to multiple servers in distinct consoles easily and then to type in multiple console simultaneously.
csshX is for Mac OS X, but the tool exists for linux as well, it is called cssh.
Configure and run cssxh
To make using csshx easier, it is possible to save ‘clusters’ (actually custom lists of servers) by adding or modifying the configuration file /etc/clusters. This file uses the format described in the documentation:
<tag> [user@]<server> [user@]<server> [...]
Example:
Alains-MacBook-Pro:~ alain$ cat /etc/clusters
test 127.0.0.1 alain@127.0.0.2 127.0.0.3:22 alain@127.0.0.4:22
Then opening all the terminals, for the test cluster, is as easy as running:
csshx test
Here is a standard view of using csshx
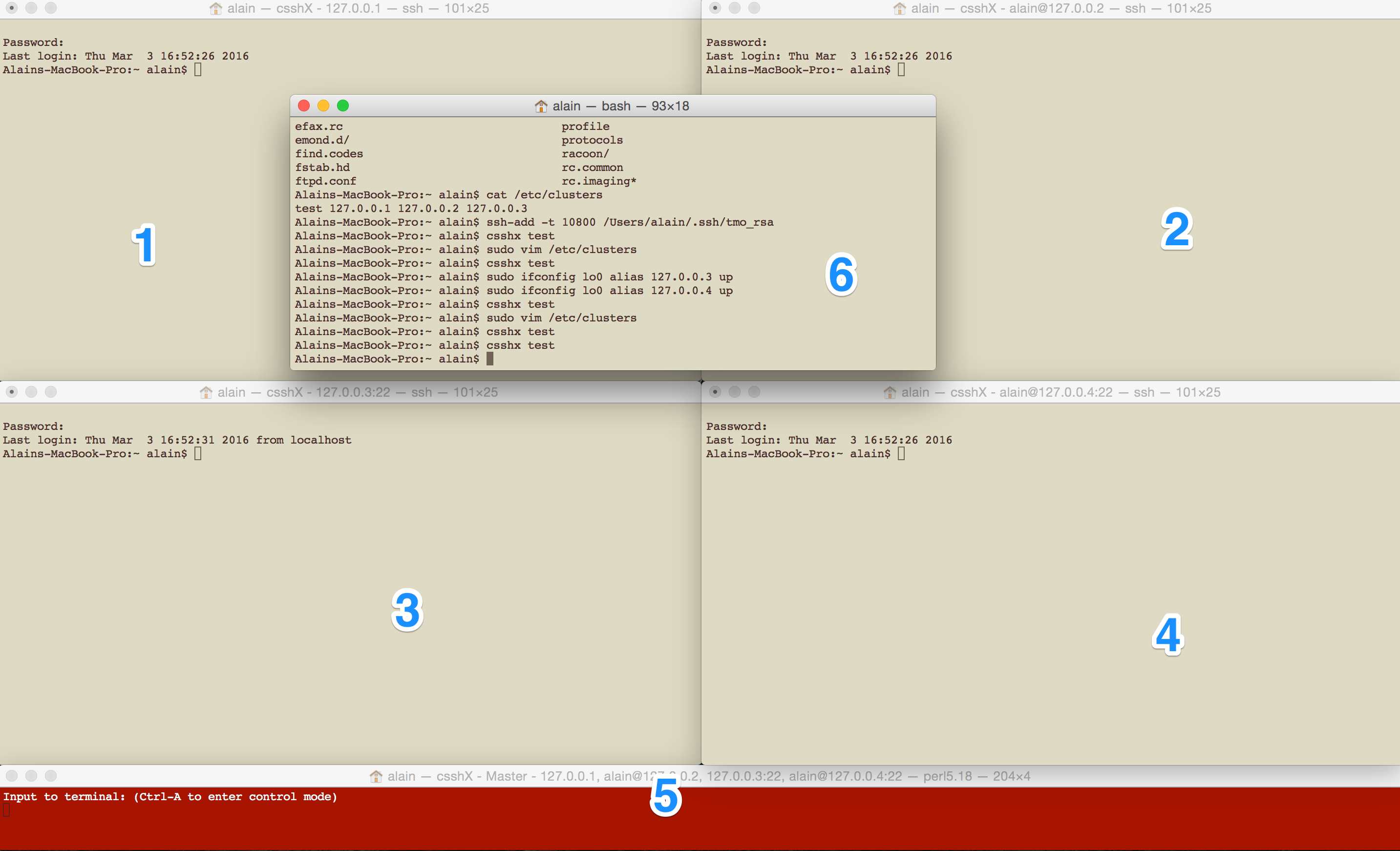
In this picture, the consoles #1 to #4 are the remote connections opened, the #5 is the ‘master’ console and the #6 is the original console where I ran the csshx command from.
Running any command from the ‘master’ console (#5) will send it at the same time to all the ‘slave’ consoles (#1 to #4)
It is possible to use only a ‘slave’ console by selecting it window. Remember to click back on the ‘master’ console to start sending to all the ‘slave’ consoles again.
Some options are available, to display console on multiple screen and some other nice features. Use the man option to see all the available options:
csshx -m
csshx -h
Strengths and Limits
Having the servers physically displayed via an open terminal in every node is great since it allows a visual control on everything. You can then easily monitor all the nodes, focusing on the bad one just with a click, which is awesome.
csshx also allows to edit configuration files from every node at the same time and then edit them all together or separately. It is also possible to past a config which is nice and removes a lot of repetitive and error prone manual work.
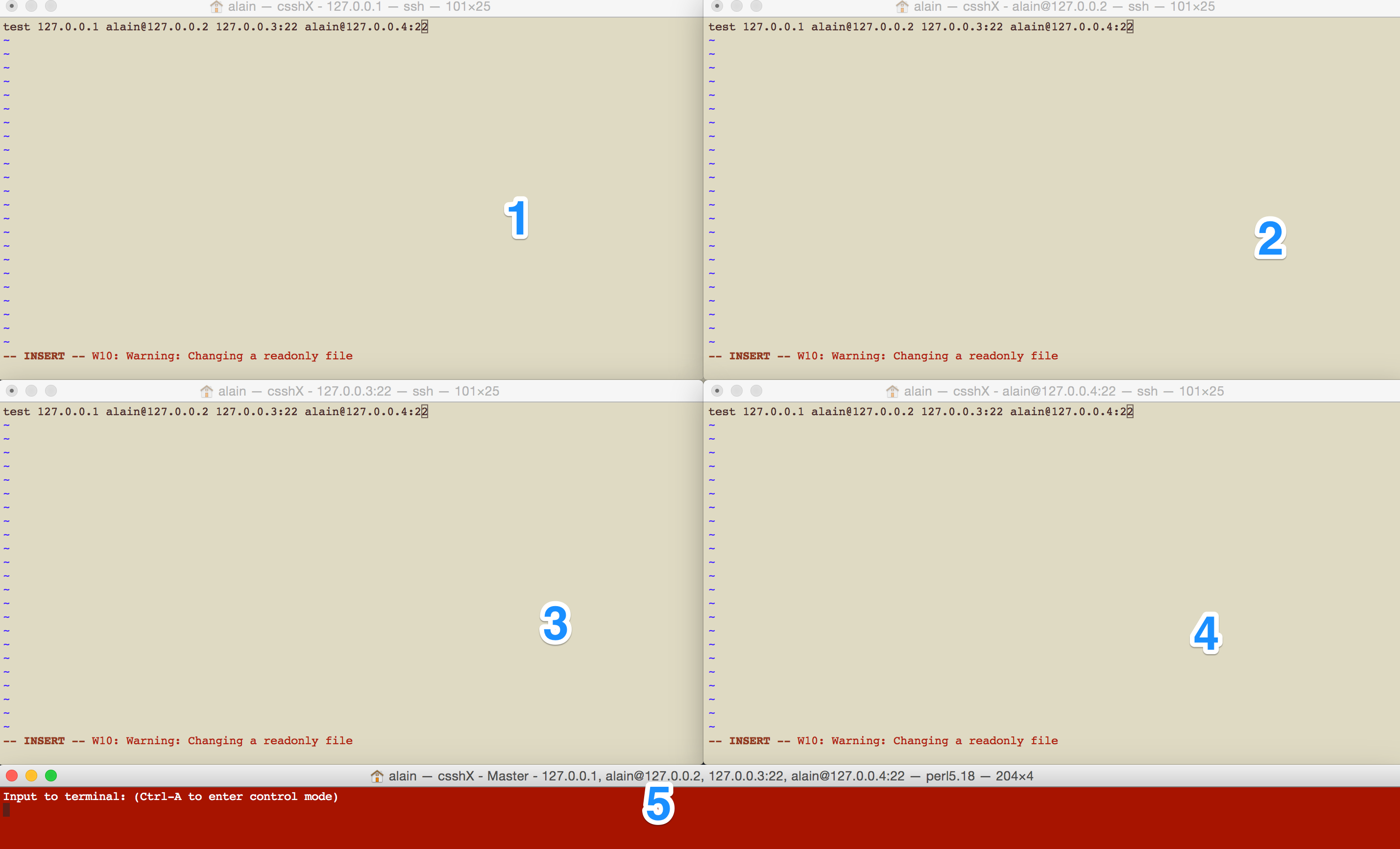
Yet, as every node is displayed depending on the screen size, the number of screen and the number of nodes, csshx can quickly become quite tricky to use and far less efficient.
Bigger number of nodes / Running scripts
As you might imagine, when the csshx console are too small it becomes very hard to use. If for some reason no automation or management tool (such as Chef, Ansible, Salt) is set up, then the following tips might be of some use.
The main idea is that if we can’t or don’t want to manage all the servers using csshx, then we need to centralize all the outputs and run the commands from one node.
To make this easy to use to anyone I quickly scripted a one-liner I use when no better option is available, and made it available on github.
See the readme file for more information on how to use it.
Those tools allowing to manage a list of servers is very powerful and efficient as it is possible to drop scripts on all the nodes and run them, allowing to perform complex operations as rolling upgrades in a fully automated way. Yet powerful tools are also often more risky. It is important to be careful as any error will be repeated the same way on all the servers sequentially. Make sure to write scripts that perform checks the same way you would have manually done. Also, keep an eye during the process, be ready to interrupt it if needed. A last advice to mitigate the risks is to go one rack at the time by selecting nodes from one rack in the script, if using enough racks or Availability Zones.
Example: Safe rolling restart
Let’s say we just change something in the configuration for all nodes and now want to apply it by running a rolling restart. I generated a small test cluster on AWS for the following example. Machines are out of the box using the Datastax AMI (community).
-
Copy the script on the node you use to operate (should be able to access through ssh to all the nodes).
curl -Os https://raw.githubusercontent.com/arodrime/cassandra-tools/master/rolling-ssh/rolling-cmd.sh chmod u+x rolling-cmd.sh -
Edit the script and change the configuration in the ‘User defined variables’ block.
# Define the user name for ssh access. ubuntu in my case user=ubuntu # Change this to use a file or something else than nodetool to get addresses of the nodes. # This worked for me as is using the Datastax AMI (community version) some_cassandra_node=localhost # Used to grep all the other nodes IPs node_list=$(nodetool -h $some_cassandra_node status | awk '{split($0,a," "); print a[2]}'| grep -E '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}') -
Run the command.
./rolling-cmd.sh 'ip=$(cat /etc/hostname); nodetool disablethrift && nodetool disablebinary && sleep 5 && nodetool disablegossip && nodetool drain && sleep 10 && sudo service cassandra restart && until echo "SELECT * FROM system.peers LIMIT 1;" | cqlsh $ip > /dev/null 2>&1; do echo "Node $ip is still DOWN"; sleep 10; done && echo "Node $ip is now UP"'If not using a service for cassandra, something like
nodetool stop stopdaemon && cassandracan replacesudo service cassandra restart. Also$(cat /etc/hostname)might not be the right way to get the server IP or DNS. Adjust depending on the environment.The important trick here is to check the node is up before going to the next node. This is done in the last loop:
until echo "SELECT * FROM system.peers LIMIT 1;" | cqlsh $ip. If a node have an issue, the script will hang, the time for the operator to check what is wrong and restart the node from an other session, script will then continue. This script should not produce a situation were 2 nodes are down at the same time, that’s why I call it ‘safe’. Yet the script has no protections against external nodes going down during the procedure and so possibly removing availability, so keeping an eye on the cluster state during the script execution is required. -
Result is a rolling restart going through following steps:
Datacenter: us-east =================== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns Host ID Rack UN 10.182.73.2 1.1 MB 256 ? d307f426-dc9b-4495-afdd-64be2827b85d 1b UN 10.168.88.166 910.92 KB 256 ? b3afa561-f599-4b81-9335-0bbb69722d1c 1b UN 10.166.119.139 889.08 KB 256 ? d9b77ef3-0926-4570-b8fd-0b9a772c5452 1b Datacenter: us-east =================== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns Host ID Rack DN 10.182.73.2 1.1 MB 256 ? d307f426-dc9b-4495-afdd-64be2827b85d 1b UN 10.168.88.166 915.72 KB 256 ? b3afa561-f599-4b81-9335-0bbb69722d1c 1b UN 10.166.119.139 889.08 KB 256 ? d9b77ef3-0926-4570-b8fd-0b9a772c5452 1b Datacenter: us-east =================== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns Host ID Rack UN 10.182.73.2 1.01 MB 256 ? d307f426-dc9b-4495-afdd-64be2827b85d 1b UN 10.168.88.166 915.72 KB 256 ? b3afa561-f599-4b81-9335-0bbb69722d1c 1b UN 10.166.119.139 884.27 KB 256 ? d9b77ef3-0926-4570-b8fd-0b9a772c5452 1b Datacenter: us-east =================== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns Host ID Rack UN 10.182.73.2 1.01 MB 256 ? d307f426-dc9b-4495-afdd-64be2827b85d 1b DN 10.168.88.166 915.72 KB 256 ? b3afa561-f599-4b81-9335-0bbb69722d1c 1b UN 10.166.119.139 884.27 KB 256 ? d9b77ef3-0926-4570-b8fd-0b9a772c5452 1b Datacenter: us-east =================== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns Host ID Rack UN 10.182.73.2 1.01 MB 256 ? d307f426-dc9b-4495-afdd-64be2827b85d 1b UN 10.168.88.166 1.14 MB 256 ? b3afa561-f599-4b81-9335-0bbb69722d1c 1b UN 10.166.119.139 884.27 KB 256 ? d9b77ef3-0926-4570-b8fd-0b9a772c5452 1b Datacenter: us-east =================== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns Host ID Rack UN 10.182.73.2 1.01 MB 256 ? d307f426-dc9b-4495-afdd-64be2827b85d 1b UN 10.168.88.166 1.14 MB 256 ? b3afa561-f599-4b81-9335-0bbb69722d1c 1b DN 10.166.119.139 884.27 KB 256 ? d9b77ef3-0926-4570-b8fd-0b9a772c5452 1b Datacenter: us-east =================== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns Host ID Rack UN 10.182.73.2 1.01 MB 256 ? d307f426-dc9b-4495-afdd-64be2827b85d 1b UN 10.168.88.166 1.15 MB 256 ? b3afa561-f599-4b81-9335-0bbb69722d1c 1b UN 10.166.119.139 1.17 MB 256 ? d9b77ef3-0926-4570-b8fd-0b9a772c5452 1bAlso the command will output the following:
---- Result for ubuntu@10.182.73.2 ---- * Restarting Cassandra cassandra [ OK ] Node ip-10-182-73-2 is still DOWN Node ip-10-182-73-2 is still DOWN Node ip-10-182-73-2 is still DOWN Node ip-10-182-73-2 is now UP ---- Result for ubuntu@10.168.88.166 ---- * Restarting Cassandra cassandra [ OK ] Node ip-10-168-88-166 is still DOWN Node ip-10-168-88-166 is still DOWN Node ip-10-168-88-166 is still DOWN Node ip-10-168-88-166 is now UP ---- Result for ubuntu@10.166.119.139 ---- * Restarting Cassandra cassandra [ OK ] Node ip-10-166-119-139 is still DOWN Node ip-10-166-119-139 is still DOWN Node ip-10-166-119-139 is still DOWN Node ip-10-166-119-139 is now UPIt is easy to improve the output by adding more echo command or just adding by
set -xubuntu@ip-10-166-119-139:~$ ./rolling-cmd.sh 'set -x; ip=$(cat /etc/hostname); nodetool disablethrift && nodetool disablebinary && sleep 5 && nodetool disablegossip && nodetool drain && sleep 10 && sudo service cassandra restart && until echo "SELECT * FROM system.peers LIMIT 1;" | cqlsh $ip > /dev/null 2>&1; do echo "Node $ip is still DOWN"; sleep 10; done && echo "Node $ip is now UP"' ---- Result for ubuntu@10.182.73.2 ---- ++ cat /etc/hostname + ip=ip-10-182-73-2 + nodetool disablethrift + nodetool disablebinary + sleep 5 + nodetool disablegossip + nodetool drain + sleep 10 + sudo service cassandra restart * Restarting Cassandra cassandra [ OK ] + cqlsh ip-10-182-73-2 + echo 'SELECT * FROM system.peers LIMIT 1;' + echo 'Node ip-10-182-73-2 is still DOWN' Node ip-10-182-73-2 is still DOWN + sleep 10 + echo 'SELECT * FROM system.peers LIMIT 1;' + cqlsh ip-10-182-73-2 + echo 'Node ip-10-182-73-2 is still DOWN' Node ip-10-182-73-2 is still DOWN + sleep 10 + cqlsh ip-10-182-73-2 + echo 'SELECT * FROM system.peers LIMIT 1;' + echo 'Node ip-10-182-73-2 is still DOWN' Node ip-10-182-73-2 is still DOWN + sleep 10 + cqlsh ip-10-182-73-2 + echo 'SELECT * FROM system.peers LIMIT 1;' + echo 'Node ip-10-182-73-2 is now UP' Node ip-10-182-73-2 is now UP ---- Result for ubuntu@10.168.88.166 ----
Conclusion
There are multiple ways of making operator life way easier, even without using an external automation system. Find the tool that works the best depending on what you want to do, what your skills are or what you prefer to use.
General advices:
- When you can’t see anything anymore using
csshXbecause window are too small, it is probably time to move on. Buying 5 more screens is pointless, as having a visual control on so many machines is error prone and probably slower than automating. - Editing a file on all the servers through
csshX(using vim or anything else) is awesome. You do it once and have it applied everywhere. You can visually control what you are doing. Be careful if files are different due to some node configurations not replicated cluster-wide though! - Complex operations can be scripted and then run sequentially on all the nodes using the
rolling-cmd.shscript. - Using the
rolling-cmd.shscript provide more automation and automated control,csshXis a nice way to ‘manually’ do things for small clusters.