![]()
Mick Semb Wever
Reaper 1.2 Released
We are happy to announce the release of Cassandra Reaper 1.2!
It’s been four months since the last minor release of Reaper, being 1.1. In this period the community has delivered almost three times as many new features, improvements and bug fixes, as the previous four months going back to Reaper 1.0.
Performance and Stability at Scale
With Reaper known to be deployed and tested on clusters of 500+ nodes, the stabilization efforts and performance improvements continue. Some highlights of these are:
- Improved performance for long-running Reaper instances with lots of repair runs history,
- Improved performance for Reaper instances in charge of many clusters and tables, especially when Cassandra-3+ is used for backend storage,
- Improved and Expanded Continuous Integration for Travis and CircleCI,
- Daily Rollover of logs, ensuring performance is stable day after day.
Reaper is built with the objectives of running as a distributed system while supporting repairs across multiple regions and clusters. This is no small feat and depends upon all our wonderful engaged users providing a wide variety of valuable feedback and contributions.
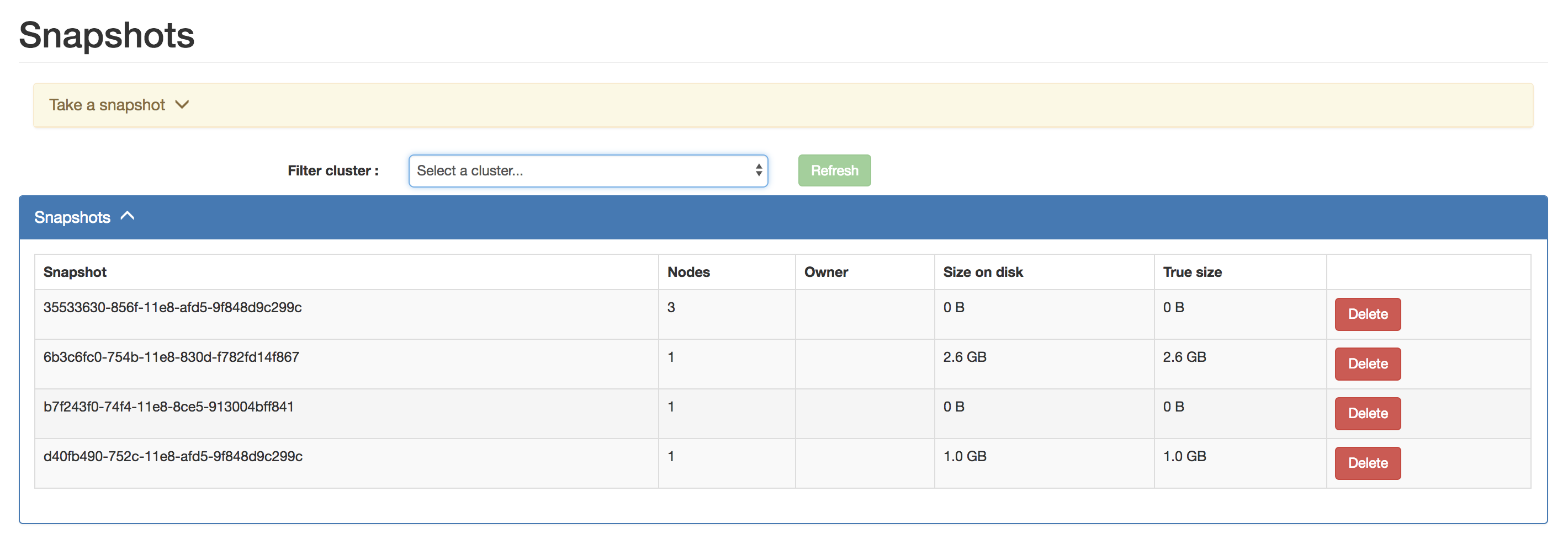
Support for Listing Snapshots
Reaper can now visualize all the snapshots in your clusters. Reaper can also take cluster-wide snapshots for you at the click of a button, or from the command line cluster-wide snapshots can now be created by using the tool.
Listing of snapshots is only supported against clusters of Cassandra-2.1+
Ease of Scripting Clusters and Schedules
With the rise of containerization, and especially immutable containers, Reaper is easier than ever to configure to start up automatically with clusters and schedules registered and ready to go. From Mesos to Kubernetes, you can feel safe that no matter how many times you redeploy new instances of Reaper, no matter how many times you wipe Reaper’s backend storage, your Cassandra clusters will always get repaired according to your schedules without ever having to touch Reaper’s UI.
The typical use-case we’ve seen so far is using spreaper in custom docker image’s entrypoint-wrapper.sh to register cluster and schedules.
This comes with the added benefit that the Reaper backend storage can now be treated as volatile space. For example when using the Cassandra backend the reaper_db keyspace can be freely deleted (when Reaper is stopped). And beyond the need for history of repair runs there’s really no reason to backup this data. (Backups are still a must when upgrading Reaper.)
We’ve also added bash completion of spreaper. Debian systems should get it installed, otherwise it needs to be run manually with
. src/packaging/etc/bash_completion.d/spreaper
Web Authentication
Your Reaper instances can now be protected with users and passwords. Authentication (and authorization) is implemented using Apache Shiro.
For more information read the documentation.
Segment Coalescing and Repair Threads
Against Cassandra-2.2+ clusters, Reaper’s repairs will now group together all token ranges that share the same replicas into common segments. For clusters using the default vnodes setting of num_tokens: 256 this results in a rather dramatic decrease in repair duration. Note that The Last Pickle recommends that new clusters are configured with num_tokens: 16 (from Cassandra-3.11, along with the use of allocate_tokens_for_local_replication_factor or allocate_tokens_for_keyspace). Also note that as token ranges get grouped together Reaper’s back-pressure mechanism: the intensity setting and checks against pending compactions; become less efficient.
For clusters running Cassandra-2.2+ Reaper now has a new option Repair Threads. This specifies how many threads can be used within a submitted repair where multiple token ranges exist. Each token range can not be processed or split by multiple threads, so the repair thread option only works where coalescing occurs.
And the selection of segments has been made simpler. Instead of selecting the total number of segments for a whole cluster, which requires a bit of contextual and variable knowledge like number of nodes and vnodes, the segment count is now per node. That is you choose how many segments you would like the repair on each node to be split into. If this selection is less than the number of vnodes than it can be expected that token ranges will be coalesced.
Automated Purging of Completed Repairs
Repair run history can really accumulate over time. While we seek to address any burdens that this ever imposes, from performance to UI clutter, we have also added the ability to routinely purge completed repair runs.
To use automatic purging configure the reaper yaml with the following options:
purgeRecordsAfterInDays: 0
numberOfRunsToKeepPerUnit: 50
Either/or of these settings can be set.
The purgeRecordsAfterInDays setting determines how many days completed repair runs are kept. A value of zero disables the feature.
The numberOfRunsToKeepPerUnit setting determines how many completed repair runs (of the same type) are kept. A value of zero disables the feature.
What’s Next for Reaper
The Reaper community is growing and we’re constantly seeing contributions coming in from new contributors. This is a wonderful sign of an establishing open source application, and we’d like to extend our thanks to Spotify for starting the Cassandra Reaper journey.
The next release of Reaper and what it holds is ultimately up to what old and new contributors offer. If you’d like to take a peek at what’s in progress take a look at our current pull requests in action. And if you’d like to influence what 1.3 or beyond looks like, get involved!
Upgrade to 1.2
The upgrade to 1.2 is recommended for all Reaper users. The binaries are available from yum, apt-get, Maven Central, Docker Hub, and are also downloadable as tarball packages. Remember to backup your database before starting the upgrade.
All instructions to download, install, configure, and use Reaper 1.2 are available on the Reaper website.