![]()
Alex Dejanovski
Reaper 1.1.0 Released
We are happy to announce the release of Cassandra Reaper 1.1.0.
Stability at Scale
Reaper 1.0 was released nearly 4 months ago and was the result of large refactorings under the hood. It was built with the objectives of safely making Reaper a distributed system and supporting repair on multi-region clusters.
The number of users ramped up was above our expectations allowing us to compile a wide variety of feedback and contributions. This community input helped us fix some stability issues that Reaper 1.0 suffered, which could lead to hanging repairs and thread leaks.
The improvements that landed in 1.1.0 were tested on single Reaper instances that manage 10s of clusters sporting 2500+ nodes overall and proved to be rock stable over the course of several weeks.
Reusable JMX Connections
All communication taking place between Reaper and the Cassandra nodes to be repaired is done through JMX. Since its inception, Reaper has created new connections each time it needed one, which meant at least one per segment and one each time it performed operations like collecting pending compactions, checking if a repair is running, or listing the nodes in a cluster.
While best efforts were made to ensure that all JMX connections were properly closed, it appeared that there were leftover JMX related threads that would pile up and possibly exhaust the server resources over time.
Thus, we had to rework the way Reaper generates and uses JMX connections so that only one is created per node and gets shared across threads. This change allowed us to fix the thread leak issue for good and will open new possibilities for subscribing to notifications that can be fired from the Cassandra nodes.
No More Hanging Repairs
Another issue that came up in 1.0 was reports of hanging repairs that would require Reaper to be restarted in order to resume segments processing.
This was especially difficult to spot as a user because Reaper didn’t offer a way to list the segments and check what was going on without parsing the logs.
Reaper 1.1.0 now allows users to view all segments from the UI, categorized by status (not started, running, done) along with the time they took to be processed. Segments can also be forcefully aborted or replayed:
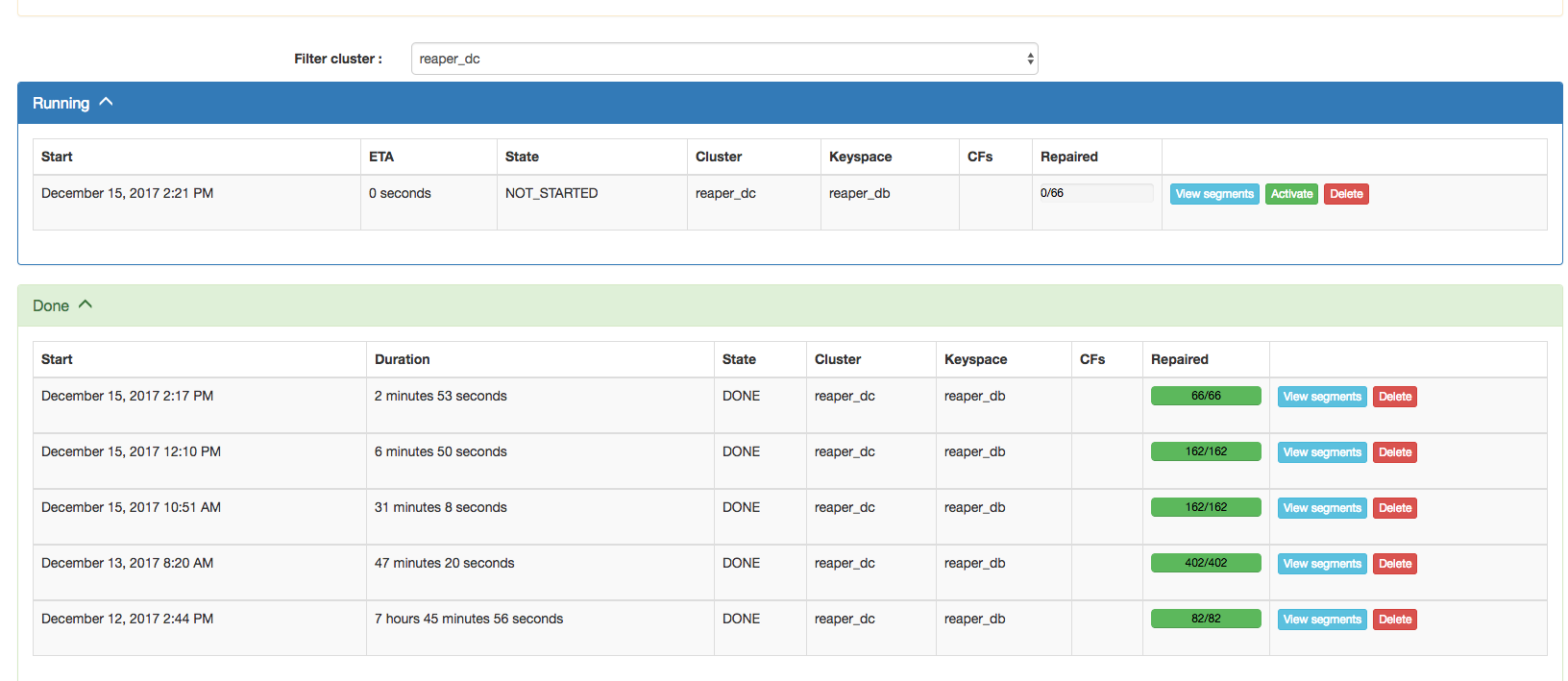
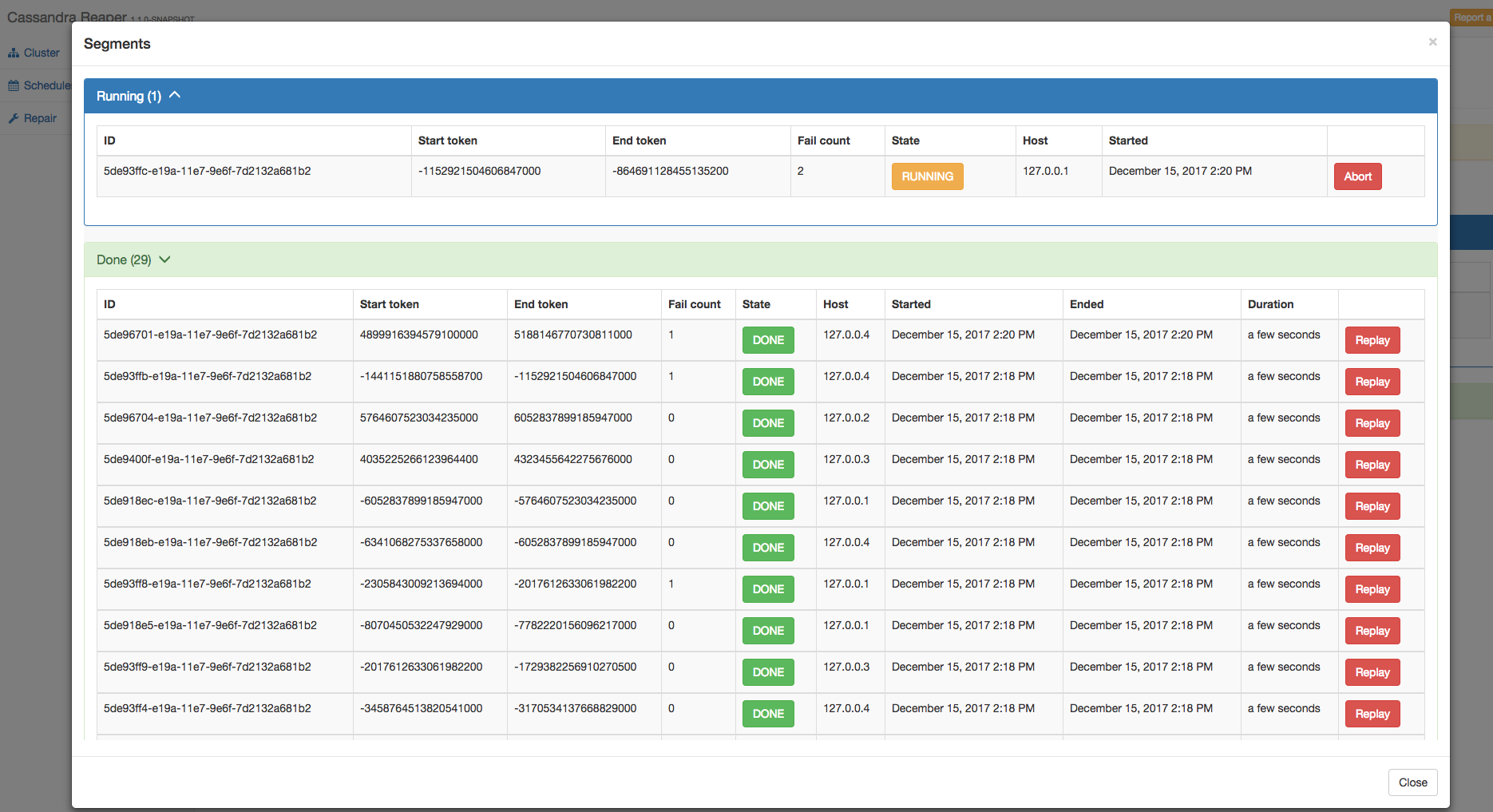
With the help of users, we also made the code more robust to exceptions and edge cases in order to prevent repairs from hanging, whatever the situation.
Lower Number of Segments with VNodes
In 1.0 we introduced a more obvious and scalable way of defining the number of segments for repairs. We moved from a global number of segments to a segment count per node. The implementation of the new segment count resulted in the generation of more segments than needed on clusters with large numbers of vnodes.
This issue is now fixed in 1.1.0 and Reaper will generate the expected number of segments.
For future releases, we are evaluating the possibility of grouping segments that would have the same replicas in order to further speed up repairs on clusters using 256 vnodes.
Improved Metrics
We wish to thank Deborah and Marshall who contributed to Reaper by adding metrics to improve tracking repair progress in monitoring tools.
Change Repair Intensity on the Fly
We also extend thanks to Kirill who made Reaper able to change intensity on a running repair. This allows users to tune it appropriately throughout the day (speed up or slow down) without having to start a whole new repair.
To achieve this through the UI, pause a running repair and click on it to display the detailed view. The intensity will appear as an input field that can be modified live. Resume the repair after changing the value and it will be taken into account instantly.
UI Usability Improvements
Testing the UI at scale showed many flaws that made it difficult to use on very large installs. This has been vastly improved in 1.1.0 and provides proper sorting of repairs, clusters, and schedules, along with enhancements for how ajax calls are scheduled.
The repair list is also limited in history depth in order to have a snappy UI even if there are hundreds of past repair runs.
What’s Next for Reaper
While the core repair features of Reaper will continue to be strengthened and improved, the next release will shift Reaper from being a repair-only tool to a full Apache Cassandra administration tool.
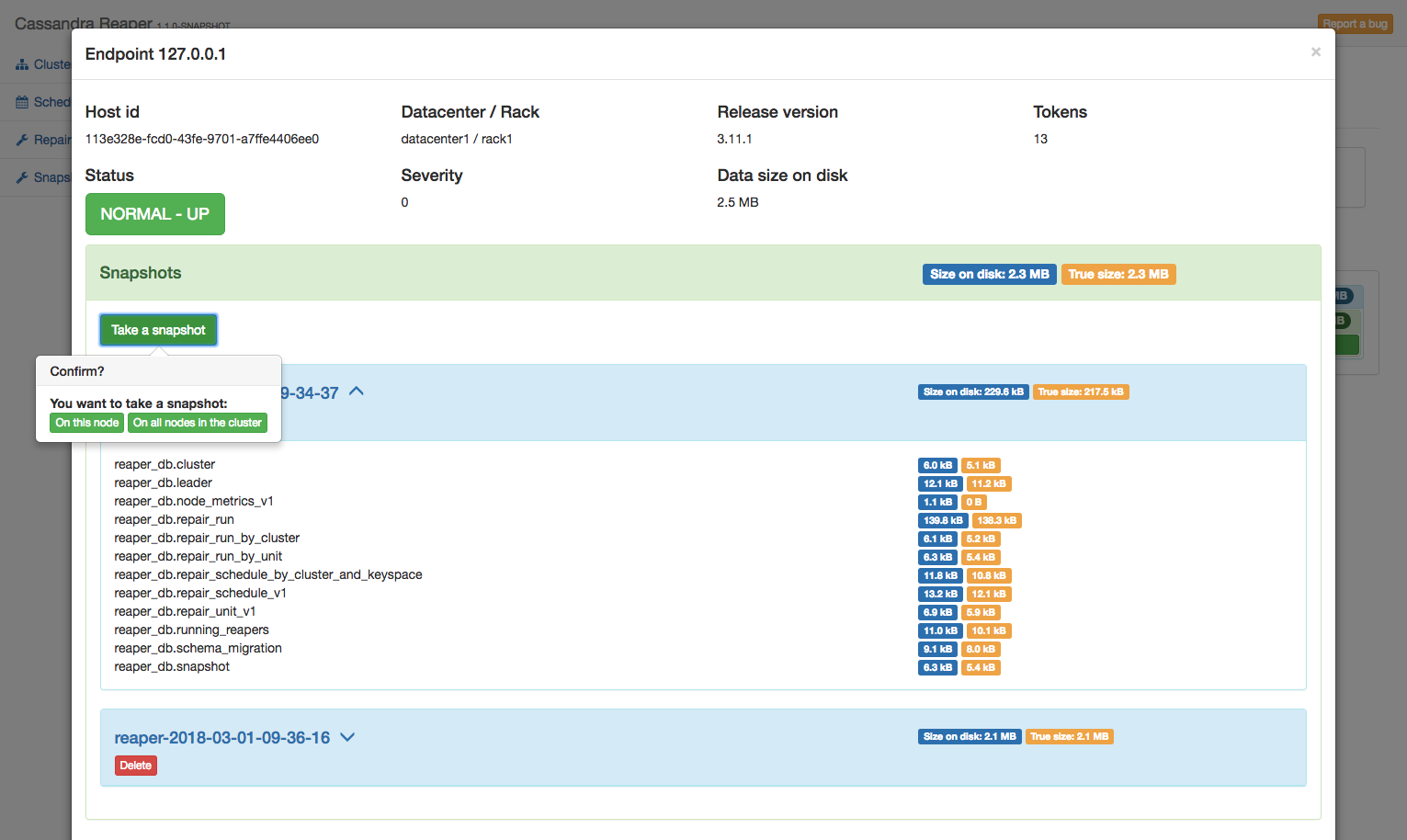
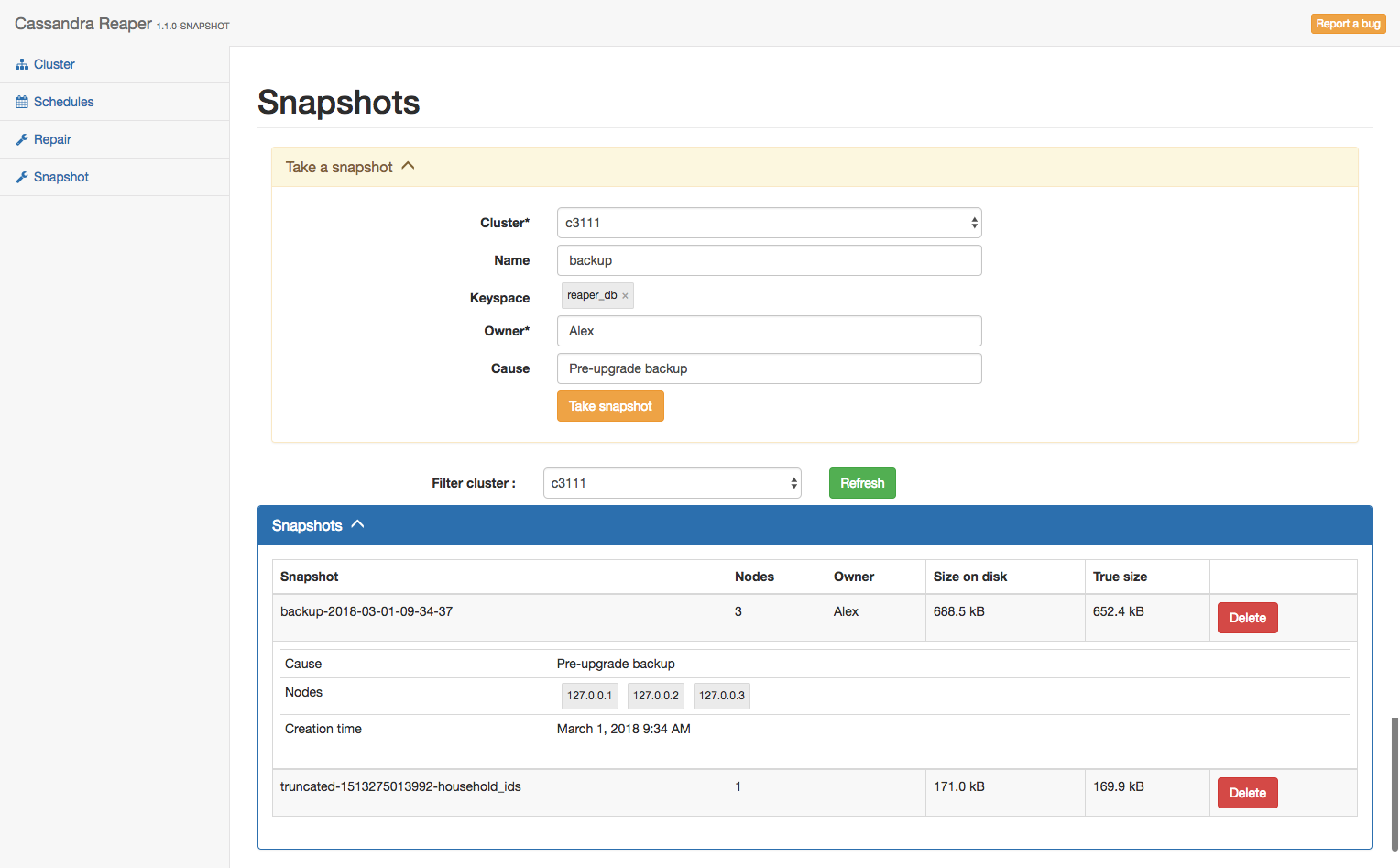
The next iteration of the project will introduce snapshot management. Reaper will be able to list all snapshots in a cluster, create them with augmented metadata (like owner and cause), and clear cluster-wide snapshots from a single click.
Snapshots can be viewed and created on specific nodes from the cluster screen:
But also for a whole cluster from a new dedicated page:
Upgrade to 1.1.0
The upgrade to 1.1.0 is highly recommended for all Reaper users. The binaries are available from yum, apt-get, Maven Central, Docker Hub, and are also downloadable as tarball packages.
All instructions to download, install, configure, and use Reaper 1.1.0 are available on the Reaper website.