![]()
Anthony Grasso
Bootstrapping Apache Cassandra Nodes
Auto bootstrapping is a handy feature when it comes to growing an Apache Cassandra cluster. There are some unknowns about how this feature works which can lead to data inconsistencies in the cluster. In this post I will go through a bit about the history of the feature, the different knobs and levers available to operate it, and resolving some of the common issues that may arise.
Summary
Here are links to the various sections of the post to give you an idea of what I will cover.
- Background
- Back to basics (how data is distributed)
- Gotchas (common mistakes and pitfalls)
- Adding a replacement node
- Hang on! What about adding a replacement a seed node?
- What to do after it completes successfully
- Help! It failed
- Testing the theory
- Conclusion
Background
The bootstrap feature in Apache Cassandra controls the ability for the data in cluster to be automatically redistributed when a new node is inserted. The new node joining the cluster is defined as an empty node without system tables or data.
When a new node joins the cluster using the auto bootstrap feature, it will perform the following operations
- Contact the seed nodes to learn about gossip state.
- Transition to Up and Joining state (to indicate it is joining the cluster; represented by
UJin thenodetool status). - Contact the seed nodes to ensure schema agreement.
- Calculate the tokens that it will become responsible for.
- Stream replica data associated with the tokens it is responsible for from the former owners.
- Transition to Up and Normal state once streaming is complete (to indicate it is now part of the cluster; represented by
UNin thenodetool status).
The above operations can be seen in the logs.
Contact the seed nodes to learn about gossip state
INFO [HANDSHAKE-/127.0.0.1] 2017-05-12 16:14:45,290 OutboundTcpConnection.java:487 - Handshaking version with /127.0.0.1
INFO [GossipStage:1] 2017-05-12 16:14:45,318 Gossiper.java:1029 - Node /127.0.0.1 is now part of the cluster
INFO [GossipStage:1] 2017-05-12 16:14:45,325 Gossiper.java:1029 - Node /127.0.0.2 is now part of the cluster
INFO [GossipStage:1] 2017-05-12 16:14:45,326 Gossiper.java:1029 - Node /127.0.0.3 is now part of the cluster
INFO [GossipStage:1] 2017-05-12 16:14:45,328 Gossiper.java:1029 - Node /127.0.0.4 is now part of the cluster
INFO [SharedPool-Worker-1] 2017-05-12 16:14:45,331 Gossiper.java:993 - InetAddress /127.0.0.1 is now UP
INFO [HANDSHAKE-/127.0.0.3] 2017-05-12 16:14:45,331 OutboundTcpConnection.java:487 - Handshaking version with /127.0.0.3
INFO [HANDSHAKE-/127.0.0.2] 2017-05-12 16:14:45,383 OutboundTcpConnection.java:487 - Handshaking version with /127.0.0.2
INFO [HANDSHAKE-/127.0.0.4] 2017-05-12 16:14:45,387 OutboundTcpConnection.java:487 - Handshaking version with /127.0.0.4
INFO [SharedPool-Worker-1] 2017-05-12 16:14:45,438 Gossiper.java:993 - InetAddress /127.0.0.3 is now UP
INFO [SharedPool-Worker-2] 2017-05-12 16:14:45,438 Gossiper.java:993 - InetAddress /127.0.0.4 is now UP
INFO [SharedPool-Worker-3] 2017-05-12 16:14:45,438 Gossiper.java:993 - InetAddress /127.0.0.2 is now UP
...
INFO [main] 2017-05-12 16:14:46,289 StorageService.java:807 - Starting up server gossip
Transition to Up and Joining state
INFO [main] 2017-05-12 16:14:46,396 StorageService.java:1138 - JOINING: waiting for ring information
Contact the seed nodes to ensure schema agreement
Take note of the last entry in this log snippet.
INFO [GossipStage:1] 2017-05-12 16:14:49,081 Gossiper.java:1029 - Node /127.0.0.1 is now part of the cluster
INFO [SharedPool-Worker-1] 2017-05-12 16:14:49,082 Gossiper.java:993 - InetAddress /127.0.0.1 is now UP
INFO [GossipStage:1] 2017-05-12 16:14:49,095 TokenMetadata.java:414 - Updating topology for /127.0.0.1
INFO [GossipStage:1] 2017-05-12 16:14:49,096 TokenMetadata.java:414 - Updating topology for /127.0.0.1
INFO [HANDSHAKE-/127.0.0.1] 2017-05-12 16:14:49,096 OutboundTcpConnection.java:487 - Handshaking version with /127.0.0.1
INFO [GossipStage:1] 2017-05-12 16:14:49,098 Gossiper.java:1029 - Node /127.0.0.2 is now part of the cluster
INFO [SharedPool-Worker-1] 2017-05-12 16:14:49,102 Gossiper.java:993 - InetAddress /127.0.0.2 is now UP
INFO [GossipStage:1] 2017-05-12 16:14:49,103 TokenMetadata.java:414 - Updating topology for /127.0.0.2
INFO [HANDSHAKE-/127.0.0.2] 2017-05-12 16:14:49,104 OutboundTcpConnection.java:487 - Handshaking version with /127.0.0.2
INFO [GossipStage:1] 2017-05-12 16:14:49,104 TokenMetadata.java:414 - Updating topology for /127.0.0.2
INFO [GossipStage:1] 2017-05-12 16:14:49,106 Gossiper.java:1029 - Node /127.0.0.3 is now part of the cluster
INFO [SharedPool-Worker-1] 2017-05-12 16:14:49,111 Gossiper.java:993 - InetAddress /127.0.0.3 is now UP
INFO [GossipStage:1] 2017-05-12 16:14:49,112 TokenMetadata.java:414 - Updating topology for /127.0.0.3
INFO [HANDSHAKE-/127.0.0.3] 2017-05-12 16:14:49,195 OutboundTcpConnection.java:487 - Handshaking version with /127.0.0.3
INFO [GossipStage:1] 2017-05-12 16:14:49,236 TokenMetadata.java:414 - Updating topology for /127.0.0.3
INFO [GossipStage:1] 2017-05-12 16:14:49,247 Gossiper.java:1029 - Node /127.0.0.4 is now part of the cluster
INFO [SharedPool-Worker-1] 2017-05-12 16:14:49,248 Gossiper.java:993 - InetAddress /127.0.0.4 is now UP
INFO [InternalResponseStage:1] 2017-05-12 16:14:49,252 ColumnFamilyStore.java:905 - Enqueuing flush of schema_keyspaces: 1444 (0%) on-heap, 0 (0%) off-heap
INFO [MemtableFlushWriter:2] 2017-05-12 16:14:49,254 Memtable.java:347 - Writing Memtable-schema_keyspaces@1493033009(0.403KiB serialized bytes, 10 ops, 0%/0% of on/off-heap limit)
INFO [MemtableFlushWriter:2] 2017-05-12 16:14:49,256 Memtable.java:382 - Completed flushing .../node5/data0/system/schema_keyspaces-b0f2235744583cdb9631c43e59ce3676/system-schema_keyspaces-tmp-ka-1-Data.db (0.000KiB) for commitlog position ReplayPosition(segmentId=1494569684606, position=119856)
INFO [InternalResponseStage:1] 2017-05-12 16:14:49,367 ColumnFamilyStore.java:905 - Enqueuing flush of schema_columnfamilies: 120419 (0%) on-heap, 0 (0%) off-heap
INFO [MemtableFlushWriter:1] 2017-05-12 16:14:49,368 Memtable.java:347 - Writing Memtable-schema_columnfamilies@1679976057(31.173KiB serialized bytes, 541 ops, 0%/0% of on/off-heap limit)
INFO [MemtableFlushWriter:1] 2017-05-12 16:14:49,396 Memtable.java:382 - Completed flushing .../node5/data0/system/schema_columnfamilies-45f5b36024bc3f83a3631034ea4fa697/system-schema_columnfamilies-tmp-ka-1-Data.db (0.000KiB) for commitlog position ReplayPosition(segmentId=1494569684606, position=119856)
...
INFO [InternalResponseStage:5] 2017-05-12 16:14:50,824 ColumnFamilyStore.java:905 - Enqueuing flush of schema_usertypes: 160 (0%) on-heap, 0 (0%) off-heap
INFO [MemtableFlushWriter:2] 2017-05-12 16:14:50,824 Memtable.java:347 - Writing Memtable-schema_usertypes@1946148009(0.008KiB serialized bytes, 1 ops, 0%/0% of on/off-heap limit)
INFO [MemtableFlushWriter:2] 2017-05-12 16:14:50,826 Memtable.java:382 - Completed flushing .../node5/data0/system/schema_usertypes-3aa752254f82350b8d5c430fa221fa0a/system-schema_usertypes-tmp-ka-10-Data.db (0.000KiB) for commitlog position ReplayPosition(segmentId=1494569684606, position=252372)
INFO [main] 2017-05-12 16:14:50,404 StorageService.java:1138 - JOINING: schema complete, ready to bootstrap
Calculate the tokens that it will become responsible for
INFO [main] 2017-05-12 16:14:50,404 StorageService.java:1138 - JOINING: waiting for pending range calculation
INFO [main] 2017-05-12 16:14:50,404 StorageService.java:1138 - JOINING: calculation complete, ready to bootstrap
INFO [main] 2017-05-12 16:14:50,405 StorageService.java:1138 - JOINING: getting bootstrap token
Stream replica data associated with the tokens it is responsible for from the former owners
Take note of the first and last entries in this log snippet.
INFO [main] 2017-05-12 16:15:20,440 StorageService.java:1138 - JOINING: Starting to bootstrap...
INFO [main] 2017-05-12 16:15:20,461 StreamResultFuture.java:86 - [Stream #604b5690-36da-11e7-aeb6-9d89ad20c2d3] Executing streaming plan for Bootstrap
INFO [StreamConnectionEstablisher:1] 2017-05-12 16:15:20,462 StreamSession.java:220 - [Stream #604b5690-36da-11e7-aeb6-9d89ad20c2d3] Starting streaming to /127.0.0.1
INFO [StreamConnectionEstablisher:2] 2017-05-12 16:15:20,462 StreamSession.java:220 - [Stream #604b5690-36da-11e7-aeb6-9d89ad20c2d3] Starting streaming to /127.0.0.2
INFO [StreamConnectionEstablisher:3] 2017-05-12 16:15:20,462 StreamSession.java:220 - [Stream #604b5690-36da-11e7-aeb6-9d89ad20c2d3] Starting streaming to /127.0.0.3
INFO [StreamConnectionEstablisher:1] 2017-05-12 16:15:20,478 StreamCoordinator.java:209 - [Stream #604b5690-36da-11e7-aeb6-9d89ad20c2d3, ID#0] Beginning stream session with /127.0.0.1
INFO [StreamConnectionEstablisher:2] 2017-05-12 16:15:20,478 StreamCoordinator.java:209 - [Stream #604b5690-36da-11e7-aeb6-9d89ad20c2d3, ID#0] Beginning stream session with /127.0.0.2
INFO [StreamConnectionEstablisher:3] 2017-05-12 16:15:20,478 StreamCoordinator.java:209 - [Stream #604b5690-36da-11e7-aeb6-9d89ad20c2d3, ID#0] Beginning stream session with /127.0.0.3
INFO [STREAM-IN-/127.0.0.2] 2017-05-12 16:15:24,339 StreamResultFuture.java:166 - [Stream #604b5690-36da-11e7-aeb6-9d89ad20c2d3 ID#0] Prepare completed. Receiving 11 files(10176549820 bytes), sending 0 files(0 bytes)
INFO [STREAM-IN-/127.0.0.3] 2017-05-12 16:15:27,201 StreamResultFuture.java:180 - [Stream #604b5690-36da-11e7-aeb6-9d89ad20c2d3] Session with /127.0.0.3 is complete
INFO [STREAM-IN-/127.0.0.1] 2017-05-12 16:15:33,256 StreamResultFuture.java:180 - [Stream #604b5690-36da-11e7-aeb6-9d89ad20c2d3] Session with /127.0.0.1 is complete
INFO [StreamReceiveTask:1] 2017-05-12 16:36:31,249 StreamResultFuture.java:180 - [Stream #604b5690-36da-11e7-aeb6-9d89ad20c2d3] Session with /127.0.0.2 is complete
INFO [StreamReceiveTask:1] 2017-05-12 16:36:31,256 StreamResultFuture.java:212 - [Stream #604b5690-36da-11e7-aeb6-9d89ad20c2d3] All sessions completed
INFO [main] 2017-05-12 16:36:31,257 StorageService.java:1167 - Bootstrap completed! for the tokens [1577102245397509090, -713021257351906154, 5943548853755748481, -186427637333122985, 89474807595263595, -3872409873927530770, 269282297308186556, -2090619435347582830, -7442271648674805532, 1993467991047389706, 3250292341615557960, 3680244045045170206, -6121195565829299067, 2336819841643904893, 8366041580813128754, -1539294702421999531, 5559860204752248078, 4990559483982320587, -5978802488822380342, 7738662906313460122, -8543589077123834538, 8470022885937685086, 7921538168239180973, 5167628632246463806, -8217637230111416952, 7867074371397881074, -6728907721317936873, -5403440910106158938, 417632467923200524, -5024952230859509916, -2145251677903377866, 62038536271402824]
Transition to Up and Normal state once streaming is complete
INFO [main] 2017-05-12 16:36:31,348 StorageService.java:1715 - Node /127.0.0.5 state jump to NORMAL
During the bootstrapping process, the new node joining the cluster has no effect on the existing data in terms of Replication Factor (RF). However, the new node will accept new writes for the token ranges acquired while existing data from the other nodes is being streamed to it. This ensures that no new writes are missed while data changes hands. In addition, it ensures that Consistency Level (CL) is respected all the time during the streaming process and even in the case of bootstrap failure. Once the bootstrapping process for the new node completes, it will begin to serve read requests (and continue to receive writes). Like the pre-existing nodes in the cluster, it too will then have an effect on the data in terms of RF and CL.
While the bootstrapping feature can be a time saver when expanding a cluster, there are some “gotchas” that are worth noting. But before we do, we need first revisit some basics.
Back to basics
Cassandra uses a token system to work out which nodes will hold which partition keys for the primary replica of data. To work out where data is stored in the cluster, Cassandra will first apply a hashing function to the partition key. The generated hash is then used to calculate a token value using an algorithm; most commonly Murmur3 or RandomPartitioner.
As seen from the log snippets, when a new node is added to the cluster it will calculate the tokens of the different data replicas that is to be responsible for. This process where tokens are calculated and acquired by the new node is often referred to as a range movement. i.e. token ranges are being moved between nodes. Once the range movement has completed, the node will by default begin the bootstrapping process where it streams data for the acquired tokens from other nodes.
Gotchas
Range movements
Whilst range movements may sound simple, the process can create implications with maintaining data consistency. A number of patches have been added over time to help maintain data consistency during range movements. A fairly well known issue was CASSANDRA-2434 where it was highlighted that range movements violated consistency for Apache Cassandra versions below 2.1.x using vnodes.
A fix was added for the issue CASSANDRA-2434 to ensure range movements between nodes were consistent when using vnodes. Prior to this patch inconsistencies could be caused during bootstrapping as per the example Jeff Jirsa gave on the dev mailing list.
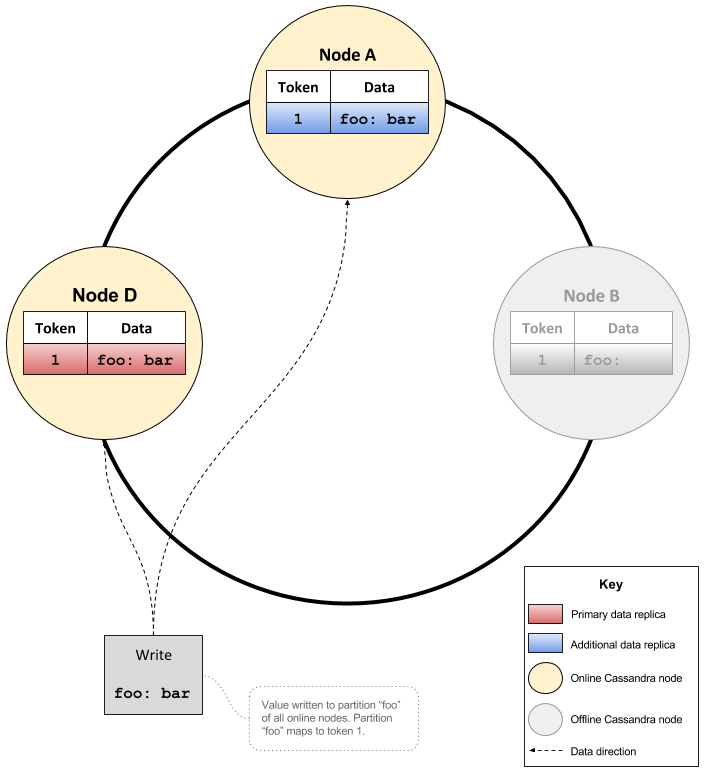
Consider the case of a cluster containing three nodes A, B and D with a RF of 3. If node B was offline and a key ‘foo’ was written with CL of QUORUM, the value for key ‘foo’ would go to nodes A and D.
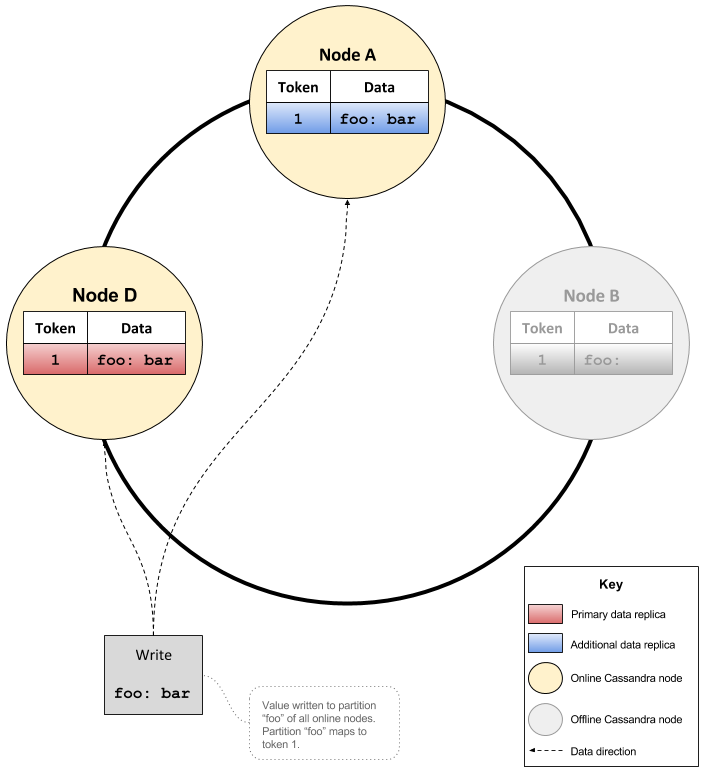
At a later point in time node B is resurrected and added back into the cluster. Around the same time a node C is added to the cluster and begins bootstrapping.
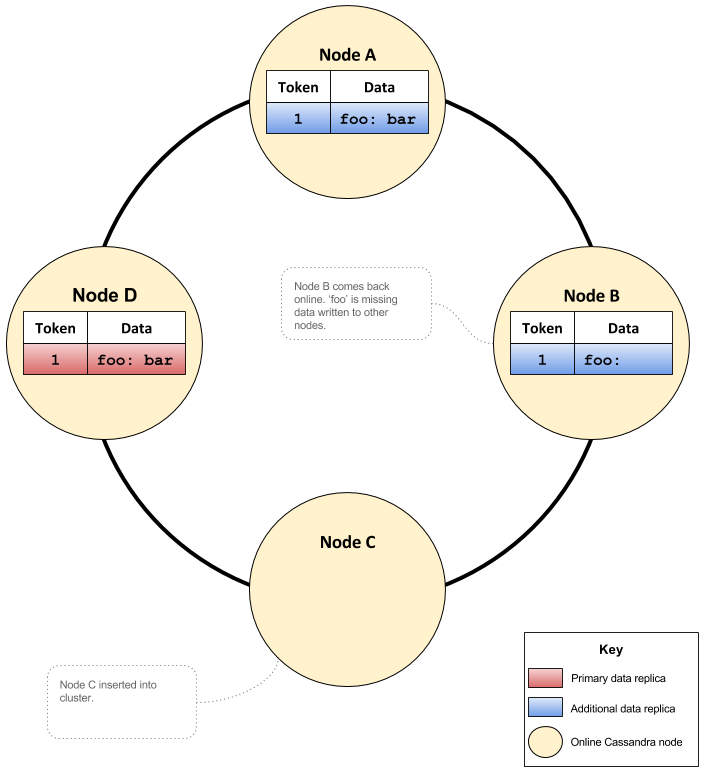
One of the tokens node C calculates and acquires during the bootstrap process is for key ‘foo’. Node B is the closest node with data for the newly acquired token and thus node C begins streaming from the neighbouring node B. This process violates the consistency guarantees of Cassandra. This is because the data on node C will be the same as node B, and both are missing the value for key ‘foo’.
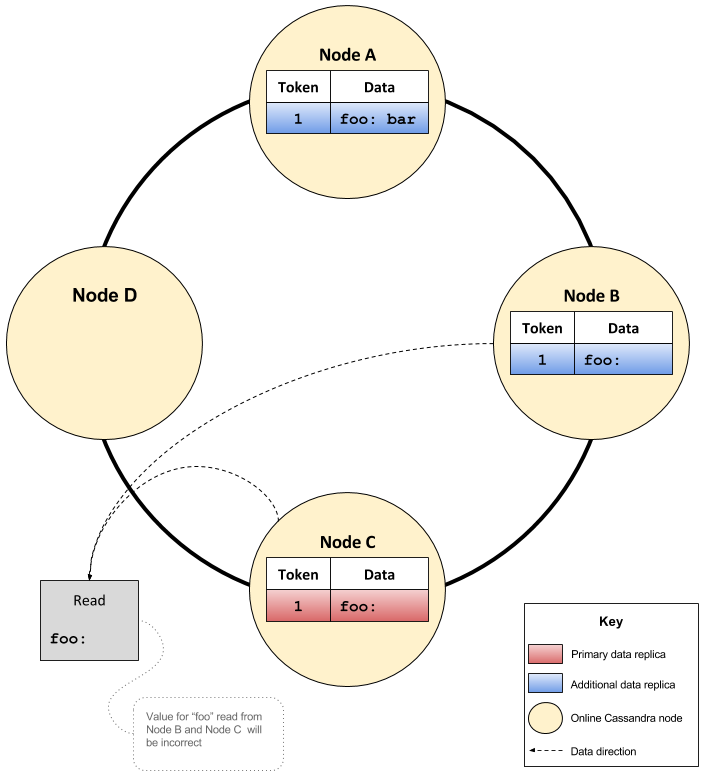
Thus, a query with a CL of QUORUM may query nodes B and C and return no data which is incorrect, despite there being data for ‘foo’ on node A. Node D previously had the correct data, but it stopped being a replica after C was inserted into the cluster.
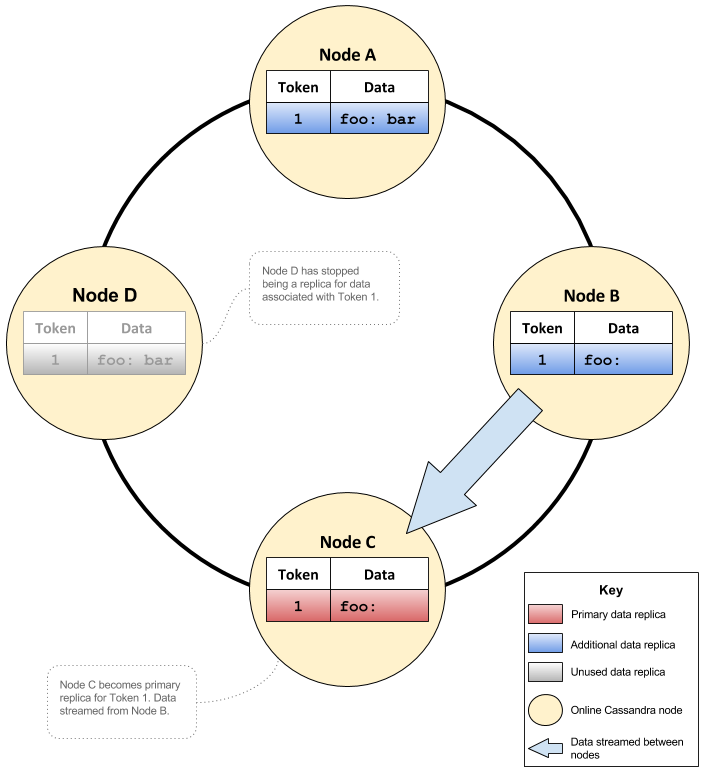
The above issue was solved in CASSANDRA-2434 by changing the default behaviour to always trying to perform a consistent range movement. That is, when node C is added (in the previous example), data is streamed from the correct replica it is replacing, node D. In this case all queries with CL of QUORUM for the key ‘foo’ would always return the correct value.
The JVM option cassandra.consistent.rangemovement was added as part of this patch. The option allows consistent range movements during bootstrapping to be disabled should the user desire this behaviour. This fix is no silver bullet though, because it requires that the correct node be available for a consistent range moment during a bootstrap. This may not always be possible, and in such cases there are two options:
- Get the required node back online (preferred option).
- If the required node is unrecoverable, set
JVM_OPTS="$JVM_OPTS -Dcassandra.consistent.rangemovement=false"in the cassandra-env.sh file to perform inconsistent range movements when auto bootstrapping. Once bootstrapping is complete, a repair will need to be run using the following command on the node. This is to ensure the data it streamed is consistent with the rest of the replicas.
nodetool repair -full
Adding multiple nodes
Another common cause of grief for users was bootstrapping multiple node simultaneously; captured in CASSANDRA-7069. Adding two new nodes simultaneously to a cluster could potentially be harmful, given the operations performed by a new node when joining. Waiting two minutes for the gossip state to propagate before adding a new node is possible, however as noted in CASSANDRA-9667, there is no coordination between nodes during token selection. For example consider that case if Node A was bootstrapped, then two minutes later Node B was bootstrapped. Node B could potentially pick token ranges already selected by Node A.
The above issue was solved in CASSANDRA-7069 by changing the default behaviour such that adding a node would fail if another node was already bootstrapping in a cluster. Similar to CASSANDRA-2434, this behaviour could be disabled by setting the JVM option JVM_OPTS="$JVM_OPTS -Dcassandra.consistent.rangemovement=false" in the cassandra-env.sh file on the bootstrapping node. This means that if cassandra.consistent.rangemovement=false is set to allow multiple nodes to bootstrap, the cluster runs the risk of violating consistency guarantees because of CASSANDRA-2434.
Changes made by CASSANDRA-7069 mean that the default behaviour forces a user to add a single node at a time to expand the cluster. This is the safest way of adding nodes to expand a cluster and ensure that the correct amount of data is streamed between nodes.
Data streaming
To further add to the confusion there is a misconception about what the auto_bootstrap property does in relation to a node being added to the cluster. Despite its name, this property controls the data streaming step only in the bootstrap process. The boolean property is by default set to true. When set to true, the data streaming step will be performed during the bootstrap process.
Setting auto_bootstrap to false when bootstrapping a new node exposes the cluster to huge inconsistencies. This is because all the other steps in the process are carried out but no data is streamed to the node. Hence, the node would be in the UN state without having any data for the token ranges it has been allocated! Furthermore, the new node without data will be serving reads and nodes that previously owned the tokens will no longer be serving reads. Effectively, the token ranges for that replica would be replaced with no data.
It is worth noting that the other danger to using auto_bootstrap set to false is no IP address collision check occurs. As per CASSANDRA-10134, if a new node has auto_bootstrap set to false and has the same address as an existing down node, the new node will take over the token range of the old node. No error is thrown, only a warning messages such as the following one below is written to the logs of the other nodes in the cluster. At the time of writing this post, the fix for this issue only appears in Apache Cassandra version 3.6 and above.
WARN [GossipStage:1] 2017-05-19 17:35:10,994 TokenMetadata.java:237 - Changing /127.0.0.3's host ID from 1938db5d-5f23-46e8-921c-edde18e9c829 to c30fbbb8-07ae-412c-baea-90865856104e
The behaviour of auto_bootstrap: false can lead to data inconsistencies in the following way. Consider the case of a cluster containing three nodes A, B and D with a RF of 3. If node B was offline and a key ‘foo’ was written with CL of QUORUM, the value for key ‘foo’ would go to nodes A and D. In this scenario Node D is the owner of the token relating to the key ‘foo’.
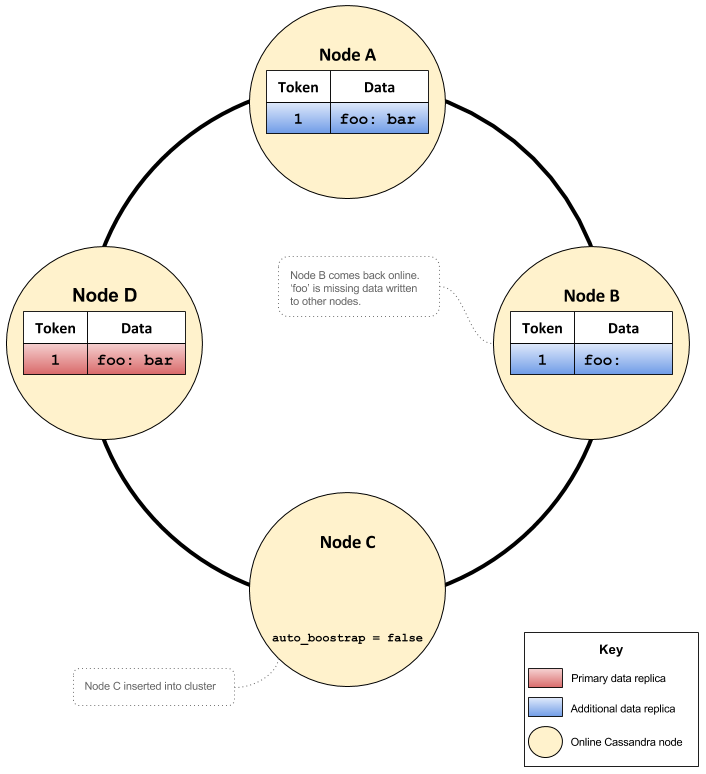
At a later point in time node B is resurrected and added back into the cluster. Around the same time a node C is added to the cluster with auto_bootstrap set to false and begins the joining process.
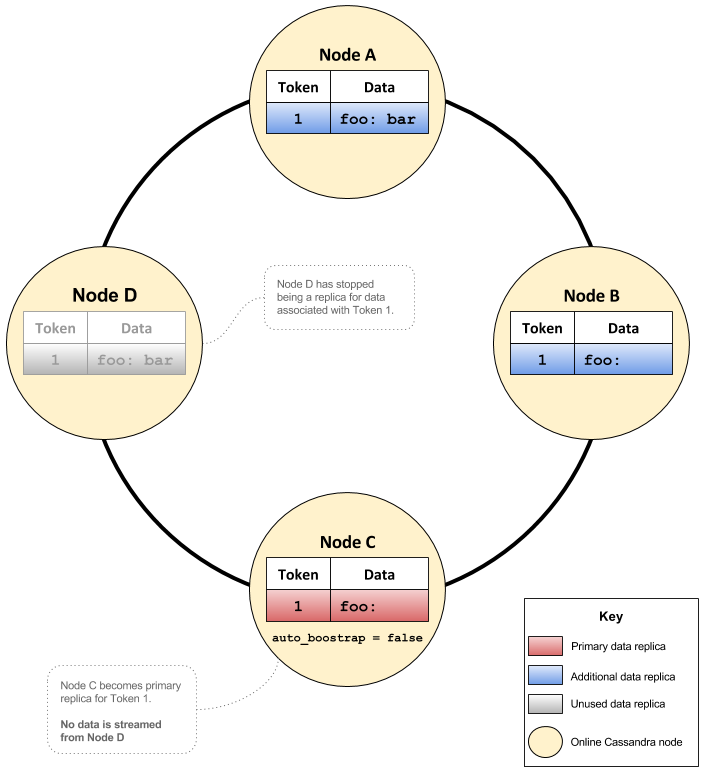
One of the tokens node C calculates and acquires during the bootstrap process is for key ‘foo’. Now node D is no longer the owner and hence its data for the key ‘foo’ will no longer be used during reads/writes. This process causes inconsistencies in Cassandra because both nodes B and C contain no data for key ‘foo’.
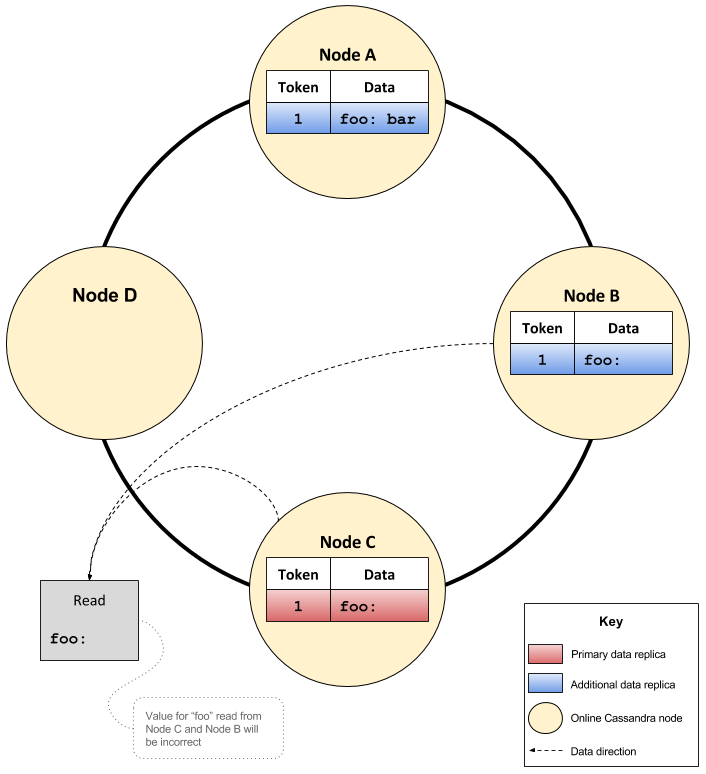
Thus, a query with a CL of QUORUM may query nodes B and C and return no data which is incorrect, despite there being data for ‘foo’ on node A. Node D previously had data, but it stopped being a replica after C was inserted.
This confusing behaviour is one of the reasons why if you look into the cassandra.yaml file you will notice that the auto_bootstrap configuration property is missing. Exposure of the property in the cassandra.yaml was short lived, as it was removed via CASSANDRA-2447 in version 1.0.0. As a result, the property is hidden and its default value of true means that new nodes will stream data when they join the cluster.
Adding a replacement node
So far we have examined various options that control the bootstrapping default behaviour when a new node is added to a cluster. Adding a new node is just one case where bootstrapping is performed, what about the case of replacing a node in the cluster if one goes down?
Should an existing node go down and needs to be replaced, the JVM option cassandra.replace_address can be used. Note that this option is only available for Apache Cassandra versions 2.x.x and higher. This feature has been around for a while and blogged about by other users in the past.
As the name suggests, it effectively replaces a down or dead node in the cluster with a new node. It is because of this that replace address option should only be used if the node is in a Down and Normal state (represented by DN in the nodetool status). Furthermore, there are no range movements that occur when using this feature, the new replacement node will simply inherit the old dead node’s token ranges. This is simpler than decommissioning the dead node and bootstrapping a fresh one, which would involve two range movements and two streaming phases. Yuck! To use the option, simply add JVM_OPTS="$JVM_OPTS -Dcassandra.replace_address=<IP_ADDRESS>" to the cassandra-env.sh file of the new node that will be replacing the old node. Where <IP_ADDRESS> is the IP address of the node to be replaced.
Once the node completes bootstrapping and joins the cluster, the JVM_OPTS="$JVM_OPTS -Dcassandra.replace_address=<IP_ADDRESS>" option must be removed from the cassandra-env.sh file or the node will fail to start on a restart. This is a short coming of the cassandra.replace_address feature. Many operators will typically be worried about a dead node being replaced and as a result forget to update the cassandra-env.sh file after the job is complete. It was for this reason that CASSANDRA-7356 was raised and resulted in a new option being added; cassandra.replace_address_first_boot. This option works once when Cassandra is first started and the replacement node inserted into the cluster. After that, the option is ignored for all subsequent restarts. It works in the same way as its predecessor; simply add JVM_OPTS="$JVM_OPTS -Dcassandra.replace_address_first_boot=<IP_ADDRESS>" to the cassandra-env.sh and the new node is ready to be inserted.
Hang on! What about adding a replacement a seed node?
Ok, so you need to replace a seed node. Seed nodes are just like every other node in the cluster. As per the Apache Cassandra documentation, the only difference being seed nodes are the go to node when a new node joins the cluster.
There are a few extra steps to replace a seed node and bootstrap a new one in its place. Before adding the replacement seed node, the IP address of the seed node will need to be removed from the seed_provider list in the cassandra.yaml file and replaced with another node in the cluster. This needs to be done for all the nodes in the cluster. Naturally, a rolling restart will need to be performed for the changes to take effect. Once the change is complete the replacement node can be inserted as described in the previous section of this post.
What to do after it completes successfully
Once your node has successfully completed the bootstrapping process, it will transition to Up and Normal state (represented by UN in the nodetool status) to indicate it is now part of the cluster. At this point it is time to cleanup the nodes on your cluster. Yes, your nodes are dirty and need to be cleaned. “Why?” you ask, well the reason is the data that has been acquired by the newly added node still remains on the nodes that previously owned it. Whilst the nodes that previously owned the data have streamed it to the new node and relinquished the associated tokens, the data that was streamed still remains on the original nodes. This “orphaned” data is consuming valuable disk space, and in the cases large data sets; probably consuming a significant amount.
However, before running off to the console to remove the orphaned data from the nodes, make sure it is done as a last step in a cluster expansion. If the expansion of the cluster requires only one node to be added, perform the cleanup after the node has successfully completed bootstrapping and joined the cluster. If the expansion requires three nodes to be added, perform the cleanup after all three nodes have successfully completed bootstrapping and joined the cluster. This is because the cleanup will need to be executed on all nodes in the cluster, except for the last node that was added to the cluster. The last node added to the cluster will contain only the data it needed for the tokens acquired, where as other nodes may contain data for tokens they no longer have. It is still ok to run cleanup on the last node, it will likely return immediately after it is called.
The cleanup can be executed on each node using the following command.
nodetool cleanup -j <COMPACTION_SLOTS>
Where
<COMPACTION_SLOTS> is the number of compaction slots to use for cleanup. By default this is 2. If set to 0 it will use use all available compaction threads.
It is probably worth limiting the number of compaction slots used by cleanup otherwise it could potentially block compactions.
Help! It failed
The bootstrap process for a joining node can fail. Bootstrapping will put extra load on the network so should bootstrap fail, you could try tweaking the streaming_socket_timeout_in_ms. Set streaming_socket_timeout_in_ms in the cassandra.yaml file to 24 hours (60 * 60 * 24 * 1000 = 86,400,000ms). Having a socket timeout set is crucial for catching streams that hang and reporting them via an exception in the logs as per CASSANDRA-11286.
If the bootstrap process fails in Cassandra version 2.1.x, the process will need to be restarted all over again. This can be done using the following steps.
- Stop Cassandra on the node.
- Delete all files and directories from the data, commitlog and save_cache directories but leave the directories there.
- Wait about two minutes.
- Start Cassandra on the node.
If the bootstrap process fails in Cassandra 2.2.x, the process can be easily be resumed using the following command thanks to CASSANDRA-8942.
nodetool bootstrap resume
Testing the theory
We have gone through a lot of theory in this post, so I thought it would be good to test some of it out to demonstrate what can happen when bootstrapping multiple nodes at the same time.
Setup
In my test I used a three node local cluster running Apache Cassandra 2.1.14 which was created with the ccm tool. Each node was configured to use vnodes; specifically num_tokens was set to 32 in the cassandra.yaml file. The cluster was loaded with around 20 GB of data generated from the killrweather dataset. Data loading was performed in batches using cdm. Prior to starting the test the cluster looked like this.
$ ccm node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 127.0.0.1 19.19 GB 32 29.1% cfb50e13-52a4-4821-bca2-4dba6061d38a rack1
UN 127.0.0.2 9.55 GB 32 37.4% 5176598f-bbab-4165-8130-e33e39017f7e rack1
UN 127.0.0.3 19.22 GB 32 33.5% d261faaf-628f-4b86-b60b-3825ed552aba rack1
It was not the most well balanced cluster, however it was good enough for testing. It should be noted that the node with IP address 127.0.0.1 was set to be the only seed node in the cluster. Taking a quick peak at the keyspace configuration in using CQLSH and we can see that it was using replication_factor: 1 i.e. RF = 1.
cqlsh> describe killrweather
CREATE KEYSPACE killrweather WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '1'} AND durable_writes = true;
Adding a new node
A new node (node4) was added to the cluster.
$ ccm node4 start
After a minute or so node4 was in the UJ state and began the bootstrap process.
$ ccm node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 127.0.0.1 19.19 GB 32 29.1% cfb50e13-52a4-4821-bca2-4dba6061d38a rack1
UN 127.0.0.2 9.55 GB 32 37.4% 5176598f-bbab-4165-8130-e33e39017f7e rack1
UN 127.0.0.3 19.22 GB 32 33.5% d261faaf-628f-4b86-b60b-3825ed552aba rack1
UJ 127.0.0.4 14.44 KB 32 ? ae0a26a6-fab5-4cab-a189-697818be3c95 rack1
It was observed that node4 had started streaming data from node1 (IP address 127.0.0.1) and node2 (IP address 127.0.0.2).
$ ccm node4 nodetool netstats
Mode: JOINING
Bootstrap f4e54a00-36d9-11e7-b18e-9d89ad20c2d3
/127.0.0.1
Receiving 9 files, 10258729018 bytes total. Already received 2 files, 459059994 bytes total
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-3-Data.db 452316846/452316846 bytes(100%) received from idx:0/127.0.0.1
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-2-Data.db 6743148/6743148 bytes(100%) received from idx:0/127.0.0.1
/127.0.0.3
/127.0.0.2
Receiving 11 files, 10176549820 bytes total. Already received 1 files, 55948069 bytes total
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-1-Data.db 55948069/55948069 bytes(100%) received from idx:0/127.0.0.2
Read Repair Statistics:
Attempted: 0
Mismatch (Blocking): 0
Mismatch (Background): 0
Pool Name Active Pending Completed
Commands n/a 0 6
Responses n/a 0 471
Adding another new node
A few minutes later another new node (node5) was added to the cluster. To add this node to the cluster while node4 was bootstrapping the JVM option JVM_OPTS="$JVM_OPTS -Dcassandra.consistent.rangemovement=false" was added to the node’s cassandra-env.sh file. The node was then started.
$ ccm node5 start
After about a minute node5 was in the UJ state and it too began the bootstrap process.
$ ccm node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 127.0.0.1 19.19 GB 32 29.1% cfb50e13-52a4-4821-bca2-4dba6061d38a rack1
UN 127.0.0.2 9.55 GB 32 37.4% 5176598f-bbab-4165-8130-e33e39017f7e rack1
UN 127.0.0.3 19.22 GB 32 33.5% d261faaf-628f-4b86-b60b-3825ed552aba rack1
UJ 127.0.0.4 106.52 KB 32 ? ae0a26a6-fab5-4cab-a189-697818be3c95 rack1
UJ 127.0.0.5 14.43 KB 32 ? a71ed178-f353-42ec-82c8-d2b03967753a rack1
It was observed that node5 had started streaming data from node2 as well; the same node that node4 was streaming data from.
$ ccm node5 nodetool netstats
Mode: JOINING
Bootstrap 604b5690-36da-11e7-aeb6-9d89ad20c2d3
/127.0.0.3
/127.0.0.2
Receiving 11 files, 10176549820 bytes total. Already received 1 files, 55948069 bytes total
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-1-Data.db 55948069/55948069 bytes(100%) received from idx:0/127.0.0.2
/127.0.0.1
Read Repair Statistics:
Attempted: 0
Mismatch (Blocking): 0
Mismatch (Background): 0
Pool Name Active Pending Completed
Commands n/a 0 8
Responses n/a 0 255
The interesting point to note when looking at the netstats was that both node4 and node5 were each streaming a Data.db file exactly 55948069 bytes from node2.
Data streaming much
It had appeared that both node4 and node5 were streaming the same data from node2. This continued as the bootstrapping process progressed; the size of the files being streamed from node2 were the same for both node4 and node5. Checking the netstats on node4 produced the following.
$ ccm node4 nodetool netstats
Bootstrap f4e54a00-36d9-11e7-b18e-9d89ad20c2d3
/127.0.0.1
Receiving 9 files, 10258729018 bytes total. Already received 6 files, 10112487796 bytes total
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-13-Data.db 1788940555/1788940555 bytes(100%) received from idx:0/127.0.0.1
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-5-Data.db 7384377358/7384377358 bytes(100%) received from idx:0/127.0.0.1
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-12-Data.db 27960312/27960312 bytes(100%) received from idx:0/127.0.0.1
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-3-Data.db 452316846/452316846 bytes(100%) received from idx:0/127.0.0.1
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-11-Data.db 452149577/452149577 bytes(100%) received from idx:0/127.0.0.1
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-2-Data.db 6743148/6743148 bytes(100%) received from idx:0/127.0.0.1
/127.0.0.3
/127.0.0.2
Receiving 11 files, 10176549820 bytes total. Already received 10 files, 10162463079 bytes total
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-1-Data.db 55948069/55948069 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-9-Data.db 55590043/55590043 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-6-Data.db 901588743/901588743 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-15-Data.db 14081154/14081154 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-16-Data.db 1450179/1450179 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-8-Data.db 901334951/901334951 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-10-Data.db 3622476547/3622476547 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-17-Data.db 56277615/56277615 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-4-Data.db 3651310715/3651310715 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-7-Data.db 902405063/902405063 bytes(100%) received from idx:0/127.0.0.2
Read Repair Statistics:
Attempted: 0
Mismatch (Blocking): 0
Mismatch (Background): 0
Pool Name Active Pending Completed
Commands n/a 0 6
Responses n/a 0 4536
Then checking netstats on node5 produced the following.
$ ccm node5 nodetool netstats
Mode: JOINING
Bootstrap 604b5690-36da-11e7-aeb6-9d89ad20c2d3
/127.0.0.1
/127.0.0.3
/127.0.0.2
Receiving 11 files, 10176549820 bytes total. Already received 9 files, 10106185464 bytes total
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-2-Data.db 3651310715/3651310715 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-1-Data.db 55948069/55948069 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-9-Data.db 1450179/1450179 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-3-Data.db 901588743/901588743 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-6-Data.db 55590043/55590043 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-4-Data.db 902405063/902405063 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-8-Data.db 14081154/14081154 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-5-Data.db 901334951/901334951 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-7-Data.db 3622476547/3622476547 bytes(100%) received from idx:0/127.0.0.2
Read Repair Statistics:
Attempted: 0
Mismatch (Blocking): 0
Mismatch (Background): 0
Pool Name Active Pending Completed
Commands n/a 0 8
Responses n/a 0 4383
To be absolutely sure about what was being observed, I ran a command to order the netstats output by file size for both node4 and node5.
$ for file_size in $(ccm node4 nodetool netstats | grep '(100%)\ received' | grep '127.0.0.2' | tr -s ' ' | cut -d' ' -f3 | cut -d'/' -f1 | sort -g); do ccm node4 nodetool netstats | grep ${file_size} | tr -s ' '; done
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-16-Data.db 1450179/1450179 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-15-Data.db 14081154/14081154 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-9-Data.db 55590043/55590043 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-1-Data.db 55948069/55948069 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-17-Data.db 56277615/56277615 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-8-Data.db 901334951/901334951 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-6-Data.db 901588743/901588743 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-7-Data.db 902405063/902405063 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-10-Data.db 3622476547/3622476547 bytes(100%) received from idx:0/127.0.0.2
.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-4-Data.db 3651310715/3651310715 bytes(100%) received from idx:0/127.0.0.2
$ for file_size in $(ccm node5 nodetool netstats | grep '(100%)\ received' | grep '127.0.0.2' | tr -s ' ' | cut -d' ' -f3 | cut -d'/' -f1 | sort -g); do ccm node5 nodetool netstats | grep ${file_size} | tr -s ' '; done
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-9-Data.db 1450179/1450179 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-8-Data.db 14081154/14081154 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-6-Data.db 55590043/55590043 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-1-Data.db 55948069/55948069 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-5-Data.db 901334951/901334951 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-3-Data.db 901588743/901588743 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-4-Data.db 902405063/902405063 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-7-Data.db 3622476547/3622476547 bytes(100%) received from idx:0/127.0.0.2
.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-tmp-ka-2-Data.db 3651310715/3651310715 bytes(100%) received from idx:0/127.0.0.2
With the exception of one file being streamed by node4, killrweather-raw_weather_data-tmp-ka-17-Data.db (size 56277615 bytes), node4 and node5 looked to be streaming the same data from node2. This was the first confirmation that node5 had stolen the tokens that where originally calculated by node4. Furthermore, it looked like node 4 was performing unnecessary streaming from node2. I noted down the file sizes displayed by node5’s netstats output to help track down data files on each node.
$ ccm node5 nodetool netstats | grep '(100%)\ received' | grep '127.0.0.2' | tr -s ' ' | cut -d' ' -f3 | cut -d'/' -f1 | sort -g > file_sizes.txt; cat file_sizes.txt
1450179
14081154
55590043
55948069
901334951
901588743
902405063
3622476547
3651310715
Token and the thief
Once both nodes had finished bootstrapping and had successfully joined the cluster it looked like this.
$ ccm node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 127.0.0.1 19.19 GB 32 14.8% cfb50e13-52a4-4821-bca2-4dba6061d38a rack1
UN 127.0.0.2 9.55 GB 32 22.0% 5176598f-bbab-4165-8130-e33e39017f7e rack1
UN 127.0.0.3 19.22 GB 32 23.6% d261faaf-628f-4b86-b60b-3825ed552aba rack1
UN 127.0.0.4 19.17 GB 32 17.5% ae0a26a6-fab5-4cab-a189-697818be3c95 rack1
UN 127.0.0.5 9.55 GB 32 22.1% a71ed178-f353-42ec-82c8-d2b03967753a rack1
Using the file sizes I captured earlier from node5 netstats, I checked the data directories of node4 and node5 to confirm both nodes contained files of those sizes.
$ for file_size in $(cat file_sizes.txt); do ls -al .../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/ | grep ${file_size}; done
-rw-r--r-- 1 anthony staff 1450179 12 May 16:33 killrweather-raw_weather_data-ka-16-Data.db
-rw-r--r-- 1 anthony staff 14081154 12 May 16:33 killrweather-raw_weather_data-ka-15-Data.db
-rw-r--r-- 1 anthony staff 55590043 12 May 16:33 killrweather-raw_weather_data-ka-9-Data.db
-rw-r--r-- 1 anthony staff 55948069 12 May 16:33 killrweather-raw_weather_data-ka-1-Data.db
-rw-r--r-- 1 anthony staff 901334951 12 May 16:33 killrweather-raw_weather_data-ka-8-Data.db
-rw-r--r-- 1 anthony staff 901588743 12 May 16:33 killrweather-raw_weather_data-ka-6-Data.db
-rw-r--r-- 1 anthony staff 902405063 12 May 16:33 killrweather-raw_weather_data-ka-7-Data.db
-rw-r--r-- 1 anthony staff 3622476547 12 May 16:33 killrweather-raw_weather_data-ka-10-Data.db
-rw-r--r-- 1 anthony staff 3651310715 12 May 16:33 killrweather-raw_weather_data-ka-4-Data.db
$ for file_size in $(cat file_sizes.txt); do ls -al .../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/ | grep ${file_size}; done
-rw-r--r-- 1 anthony staff 1450179 12 May 16:36 killrweather-raw_weather_data-ka-9-Data.db
-rw-r--r-- 1 anthony staff 14081154 12 May 16:36 killrweather-raw_weather_data-ka-8-Data.db
-rw-r--r-- 1 anthony staff 55590043 12 May 16:36 killrweather-raw_weather_data-ka-6-Data.db
-rw-r--r-- 1 anthony staff 55948069 12 May 16:36 killrweather-raw_weather_data-ka-1-Data.db
-rw-r--r-- 1 anthony staff 901334951 12 May 16:36 killrweather-raw_weather_data-ka-5-Data.db
-rw-r--r-- 1 anthony staff 901588743 12 May 16:36 killrweather-raw_weather_data-ka-3-Data.db
-rw-r--r-- 1 anthony staff 902405063 12 May 16:36 killrweather-raw_weather_data-ka-4-Data.db
-rw-r--r-- 1 anthony staff 3622476547 12 May 16:36 killrweather-raw_weather_data-ka-7-Data.db
-rw-r--r-- 1 anthony staff 3651310715 12 May 16:36 killrweather-raw_weather_data-ka-2-Data.db
So both nodes contained files of the same size. I then decided to check if the files on each node that were the same size had the same data content. This check was done by performing an MD5 check of file pairs that were the same size.
$ BASE_DIR=...; DATA_DIR=data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d; for file_size in $(cat file_sizes.txt); do node_4_file=$(ls -al ${BASE_DIR}/node4/${DATA_DIR}/ | grep ${file_size} | tr -s ' ' | cut -d' ' -f9); node_5_file=$(ls -al ${BASE_DIR}/node5/${DATA_DIR}/ | grep ${file_size} | tr -s ' ' | cut -d' ' -f9); md5 ${BASE_DIR}/node4/${DATA_DIR}/${node_4_file} ${BASE_DIR}/node5/${DATA_DIR}/${node_5_file}; echo; done
MD5 (.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-16-Data.db) = a9edb85f70197c7f37aa021c817de2a2
MD5 (.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-9-Data.db) = a9edb85f70197c7f37aa021c817de2a2
MD5 (.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-15-Data.db) = 975f184ae36cbab07a9c28b032532f88
MD5 (.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-8-Data.db) = 975f184ae36cbab07a9c28b032532f88
MD5 (.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-9-Data.db) = f0160cf8e7555031b6e0835951e1896a
MD5 (.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-6-Data.db) = f0160cf8e7555031b6e0835951e1896a
MD5 (.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-1-Data.db) = 7789b794bb3ef24338282d4a1a960903
MD5 (.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-1-Data.db) = 7789b794bb3ef24338282d4a1a960903
MD5 (.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-8-Data.db) = 1738695bb6b4bd237b3592e80eb785f2
MD5 (.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-5-Data.db) = 1738695bb6b4bd237b3592e80eb785f2
MD5 (.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-6-Data.db) = f7d1faa5c59a26a260038d61e4983022
MD5 (.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-3-Data.db) = f7d1faa5c59a26a260038d61e4983022
MD5 (.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-7-Data.db) = d791179432dcdbaf9a9b315178fb04c7
MD5 (.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-4-Data.db) = d791179432dcdbaf9a9b315178fb04c7
MD5 (.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-10-Data.db) = 3e6623c2f06bcd3f5caeacee1917898b
MD5 (.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-7-Data.db) = 3e6623c2f06bcd3f5caeacee1917898b
MD5 (.../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-4-Data.db) = 8775f5df08882df353427753f946bf10
MD5 (.../node5/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-2-Data.db) = 8775f5df08882df353427753f946bf10
Now I had absolute proof that both nodes did in fact stream the same data from node2. It did look as though that when node5 joined the cluster it had taken tokens calculated by node4. If this were the case, it would mean that the data files on node4 that are the same on node5 would no longer be needed. One way to prove that there is “orphaned” data on node4 i.e. data not associated to any of node4’s tokens, would be to run cleanup on the cluster. If there is orphaned data on node4 the cleanup would technically delete all or some of those files. Before running cleanup on the cluster, I took note of the files on node4 which were the same as the ones on node5.
$ for file_size in $(cat file_sizes.txt); do ls -al .../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/ | grep ${file_size}; | tr -s ' ' | cut -d' ' -f9; done > node4_orphaned_files.txt; cat node4_orphaned_files.txt
killrweather-raw_weather_data-ka-16-Data.db
killrweather-raw_weather_data-ka-15-Data.db
killrweather-raw_weather_data-ka-9-Data.db
killrweather-raw_weather_data-ka-1-Data.db
killrweather-raw_weather_data-ka-8-Data.db
killrweather-raw_weather_data-ka-6-Data.db
killrweather-raw_weather_data-ka-7-Data.db
killrweather-raw_weather_data-ka-10-Data.db
killrweather-raw_weather_data-ka-4-Data.db
I then ran a cleanup on all the nodes in the cluster.
$ ccm node1 nodetool cleanup
$ ccm node2 nodetool cleanup
$ ccm node3 nodetool cleanup
$ ccm node4 nodetool cleanup
$ ccm node5 nodetool cleanup
$ ccm node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 127.0.0.1 9.57 GB 32 14.8% cfb50e13-52a4-4821-bca2-4dba6061d38a rack1
UN 127.0.0.2 138.92 KB 32 22.0% 5176598f-bbab-4165-8130-e33e39017f7e rack1
UN 127.0.0.3 19.22 GB 32 23.6% d261faaf-628f-4b86-b60b-3825ed552aba rack1
UN 127.0.0.4 9.62 GB 32 17.5% ae0a26a6-fab5-4cab-a189-697818be3c95 rack1
UN 127.0.0.5 9.55 GB 32 22.1% a71ed178-f353-42ec-82c8-d2b03967753a rack1
From this output it was obvious that node4 contained orphaned data. Earlier I had run a nodetool status which was just after both nodes completed bootstrapping and moved to the UN state, and prior to running cleanup. The output produced at that point showed that node4 had a Load of 19.17 GB. Now after cleanup it was showing to have a load of 9.62 GB. As a final verification, I iterated through the list of files on node4 which were the same as the ones on node5 (node4_orphaned_files.txt) and checked if they still were present on node4.
$ for file_name in $(cat node4_orphaned_files.txt); do ls .../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/${file_name}; done
ls: .../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-16-Data.db: No such file or directory
ls: .../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-15-Data.db: No such file or directory
ls: .../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-9-Data.db: No such file or directory
ls: .../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-1-Data.db: No such file or directory
ls: .../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-8-Data.db: No such file or directory
ls: .../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-6-Data.db: No such file or directory
ls: .../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-7-Data.db: No such file or directory
ls: .../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-10-Data.db: No such file or directory
ls: .../node4/data0/killrweather/raw_weather_data-32f23d1015cb11e79d0fa90042a0802d/killrweather-raw_weather_data-ka-4-Data.db: No such file or directory
As it can be seen the files were deleted as part of the cleanup on node4. Which means that during bootstrap node4 originally calculated tokens for that data. It then asked for a list of files that related to those tokens from node2 and began streaming them. A little while later node5 was added to the cluster while node4 was still bootstrapping. It then calculated tokens that overlapped with node4’s tokens. Node5 then asked for a list of files that related to those tokens from node2 and started streaming data for them as well. The issue here is node4 was never notified that it no longer required to stream files from node2. Hence, unnecessary resources were being consumed as a result of bootstrapping two nodes at the same time.
Conclusion
Auto bootstrapping combined with vnodes is probably one of the most handy features in Cassandra. It takes the pain out of manually having to move data around ensure a continuous availability while expanding the cluster in a reliable and efficient way. There a number of knobs and levers for controlling the default behaviour of bootstrapping.
Configuration properties
auto_bootstrap- controls whether data is streamed to the new node when inserted.streaming_socket_timeout_in_ms- sets socket timeout for streaming operations.
JVM options
cassandra.consistent.rangemovement- controls consistent range movements and multiple node bootstrapping.cassandra.replace_address_first_boot=<IP_ADDRESS>- allows a down node to be replaced with a new node.
As demonstrated by setting the JVM option cassandra.consistent.rangemovement=false the cluster runs the risk of over streaming of data and worse still, it can violate consistency. For new users to Cassandra, the safest way to add multiple nodes into a cluster is to add them one at a time. Stay tuned as I will be following up with another post on bootstrapping.