![]()
Alex Dejanovski
TWCS part 1 - how does it work and when should you use it ?
In this post we’ll explore a new compaction strategy available in Apache Cassandra. We’ll dig into it’s use cases, limitations, and share our experiences of using it with various production clusters.
Time Window Compaction Strategy : how does it work and when should you use it ?
Cassandra uses a Log Structured Merge Tree engine, which allows high write throughput by flushing immutable chunks of data, in the form of SSTables, to disk and deferring consistency on the read phase. Over time, more and more SSTables are written to disk, resulting in a partition having chunks in multiple SSTables, slowing down reads. To limit fragmentation of data, we use a process called compaction to merge sstables together. Several compaction strategies are available in Cassandra that merge SSTables together. These strategies are designed for different workloads and data models.
Date Tiered Compaction Strategy (DTCS) was introduced in late 2014 and had the ambitious goal of reducing write amplification and become the de facto standard for time series data in Cassandra. Write amplification is when the same data is rewritten over and over instead of just once. Writing data many times over results in increased I/O, decreases disk lifetime, and blocks other processes from using the disk.
Alas, its usage in real world clusters eventually showed it had its own set of major drawbacks, on top of a complex set of parameters that made it very hard to reason about.
Jeff Jirsa, system engineer at Crowdstrike and now a committer on the Apache Cassandra project and PMC member, created Time Window Compaction Strategy (TWCS) in an effort to address these specific issues and to quote the first slide of his Cassandra Summit 2016 talk, he did it “because everything else made him sad”.
TWCS accomplishes this by removing the tiered nature of DTCS, instead opting to perform STCS on time windowed groups of SSTables. It also uses the maximum timestamp of the sstable instead of the minimum timestamp to decide which time window each SSTable will belong to. We’ll discuss this in detail later in the post.
Description and behavior
TWCS aims at simplifying DTCS by creating time windowed buckets of SSTables that are compacted with each other using the Size Tiered Compaction Strategy. An SSTable from a bucket can never be compacted with an SSTable from another bucket, preventing the write amplification hints and repairs generate on DTCS.
TWCS uses simple parameters to avoid configuration complexity, and inherits STCS parameters :
CREATE TABLE twcs.twcs (
id int,
value int,
text_value text,
PRIMARY KEY (id, value)
) WITH CLUSTERING ORDER BY (value ASC)
AND bloom_filter_fp_chance = 0.01
AND caching = '{"keys":"ALL", "rows_per_partition":"NONE"}'
AND comment = ''
AND gc_grace_seconds = 60
AND default_time_to_live = 600
AND compaction = {'compaction_window_size': '1',
'compaction_window_unit': 'MINUTES',
'class': 'org.apache.cassandra.db.compaction.TimeWindowCompactionStrategy'}
The above statement will create a table for which SSTables created within the same minute get compacted together through STCS, ultimately creating one SSTable per minute (with microsecond resolution).
Here is what is observed on disk with our table using 1 minute buckets, a 10 minute TTL and a 1 minute gc_grace_seconds (time to wait before a tombstone can be purged). SSTables get flushed to disk until their number reaches the STCS compaction threshold (4 by default) :
Ven 8 jul 2016 07:47:17 CEST
-rw-r--r-- 1 adejanovski staff 20567 8 jul 07:47 twcs-twcs-ka-1453-Data.db
=============
Ven 8 jul 2016 07:47:22 CEST
-rw-r--r-- 1 adejanovski staff 20567 8 jul 07:47 twcs-twcs-ka-1453-Data.db
-rw-r--r-- 1 adejanovski staff 21040 8 jul 07:47 twcs-twcs-ka-1454-Data.db
=============
Ven 8 jul 2016 07:47:27 CEST
-rw-r--r-- 1 adejanovski staff 20567 8 jul 07:47 twcs-twcs-ka-1453-Data.db
-rw-r--r-- 1 adejanovski staff 21040 8 jul 07:47 twcs-twcs-ka-1454-Data.db
=============
Ven 8 jul 2016 07:47:32 CEST
-rw-r--r-- 1 adejanovski staff 20567 8 jul 07:47 twcs-twcs-ka-1453-Data.db
-rw-r--r-- 1 adejanovski staff 21040 8 jul 07:47 twcs-twcs-ka-1454-Data.db
-rw-r--r-- 1 adejanovski staff 20856 8 jul 07:47 twcs-twcs-ka-1455-Data.db
=============
Ven 8 jul 2016 07:47:37 CEST
-rw-r--r-- 1 adejanovski staff 20567 8 jul 07:47 twcs-twcs-ka-1453-Data.db
-rw-r--r-- 1 adejanovski staff 21040 8 jul 07:47 twcs-twcs-ka-1454-Data.db
-rw-r--r-- 1 adejanovski staff 20856 8 jul 07:47 twcs-twcs-ka-1455-Data.db
-rw-r--r-- 1 adejanovski staff 20921 8 jul 07:47 twcs-twcs-ka-1456-Data.db
=============
Then STCS is triggered on the 07:47 window, creating SSTable 1457:
Ven 8 jul 2016 07:47:37 CEST
-rw-r--r-- 1 adejanovski staff 89474 8 jul 07:47 twcs-twcs-ka-1457-Data.db
=============
As other SSTables get flushed to disk within the time bucket, they get compacted together :
Ven 8 jul 2016 07:47:52 CEST
-rw-r--r-- 1 adejanovski staff 89474 8 jul 07:47 twcs-twcs-ka-1457-Data.db
-rw-r--r-- 1 adejanovski staff 20268 8 jul 07:47 twcs-twcs-ka-1458-Data.db
-rw-r--r-- 1 adejanovski staff 20804 8 jul 07:47 twcs-twcs-ka-1459-Data.db
=============
Ven 8 jul 2016 07:47:57 CEST
-rw-r--r-- 1 adejanovski staff 157411 8 jul 07:47 twcs-twcs-ka-1461-Data.db
=============
Ven 8 jul 2016 07:48:02 CEST
-rw-r--r-- 1 adejanovski staff 157411 8 jul 07:47 twcs-twcs-ka-1461-Data.db
-rw-r--r-- 1 adejanovski staff 21395 8 jul 07:48 twcs-twcs-ka-1462-Data.db
-rw-r--r-- 1 adejanovski staff 175158 8 jul 07:48 twcs-twcs-tmp-ka-1463-Data.db
=============
Ven 8 jul 2016 07:48:07 CEST
-rw-r--r-- 1 adejanovski staff 180903 8 jul 07:48 twcs-twcs-ka-1463-Data.db
SSTable 1463 is the last of our first bucket that started at 07:47, and will not be compacted with newly created SSTables :
Ven 8 jul 2016 07:49:12 CEST
-rw-r--r-- 1 adejanovski staff 180903 8 jul 07:48 twcs-twcs-ka-1463-Data.db
-rw-r--r-- 1 adejanovski staff 203792 8 jul 07:49 twcs-twcs-ka-1475-Data.db
-rw-r--r-- 1 adejanovski staff 19670 8 jul 07:49 twcs-twcs-ka-1476-Data.db
=============
Ven 8 jul 2016 07:49:17 CEST
-rw-r--r-- 1 adejanovski staff 180903 8 jul 07:48 twcs-twcs-ka-1463-Data.db
-rw-r--r-- 1 adejanovski staff 203792 8 jul 07:49 twcs-twcs-ka-1475-Data.db
-rw-r--r-- 1 adejanovski staff 19670 8 jul 07:49 twcs-twcs-ka-1476-Data.db
-rw-r--r-- 1 adejanovski staff 19575 8 jul 07:49 twcs-twcs-ka-1477-Data.db
=============
Ven 8 jul 2016 07:49:22 CEST
-rw-r--r-- 1 adejanovski staff 180903 8 jul 07:48 twcs-twcs-ka-1463-Data.db
-rw-r--r-- 1 adejanovski staff 203792 8 jul 07:49 twcs-twcs-ka-1475-Data.db
-rw-r--r-- 1 adejanovski staff 19670 8 jul 07:49 twcs-twcs-ka-1476-Data.db
-rw-r--r-- 1 adejanovski staff 19575 8 jul 07:49 twcs-twcs-ka-1477-Data.db
-rw-r--r-- 1 adejanovski staff 19714 8 jul 07:49 twcs-twcs-ka-1478-Data.db
=============
Ven 8 jul 2016 07:49:27 CEST
-rw-r--r-- 1 adejanovski staff 180903 8 jul 07:48 twcs-twcs-ka-1463-Data.db
-rw-r--r-- 1 adejanovski staff 203792 8 jul 07:49 twcs-twcs-ka-1475-Data.db
-rw-r--r-- 1 adejanovski staff 86608 8 jul 07:49 twcs-twcs-ka-1480-Data.db
=============
After a while, we can see one SSTable per minute is present on disk :
Ven 8 jul 2016 08:04:02 CEST
-rw-r--r-- 1 adejanovski staff 180903 8 jul 07:48 twcs-twcs-ka-1463-Data.db
-rw-r--r-- 1 adejanovski staff 203792 8 jul 07:49 twcs-twcs-ka-1475-Data.db
-rw-r--r-- 1 adejanovski staff 220004 8 jul 07:50 twcs-twcs-ka-1488-Data.db
-rw-r--r-- 1 adejanovski staff 199687 8 jul 07:51 twcs-twcs-ka-1500-Data.db
-rw-r--r-- 1 adejanovski staff 201276 8 jul 07:52 twcs-twcs-ka-1513-Data.db
-rw-r--r-- 1 adejanovski staff 223035 8 jul 07:53 twcs-twcs-ka-1525-Data.db
-rw-r--r-- 1 adejanovski staff 200849 8 jul 07:54 twcs-twcs-ka-1537-Data.db
-rw-r--r-- 1 adejanovski staff 222678 8 jul 07:55 twcs-twcs-ka-1550-Data.db
-rw-r--r-- 1 adejanovski staff 200856 8 jul 07:56 twcs-twcs-ka-1562-Data.db
-rw-r--r-- 1 adejanovski staff 200218 8 jul 07:57 twcs-twcs-ka-1575-Data.db
-rw-r--r-- 1 adejanovski staff 220425 8 jul 07:58 twcs-twcs-ka-1587-Data.db
-rw-r--r-- 1 adejanovski staff 199402 8 jul 07:59 twcs-twcs-ka-1599-Data.db
-rw-r--r-- 1 adejanovski staff 222336 8 jul 08:00 twcs-twcs-ka-1612-Data.db
-rw-r--r-- 1 adejanovski staff 198747 8 jul 08:01 twcs-twcs-ka-1624-Data.db
-rw-r--r-- 1 adejanovski staff 203138 8 jul 08:02 twcs-twcs-ka-1636-Data.db
-rw-r--r-- 1 adejanovski staff 219365 8 jul 08:03 twcs-twcs-ka-1649-Data.db
-rw-r--r-- 1 adejanovski staff 197051 8 jul 08:04 twcs-twcs-ka-1661-Data.db
When rows reach their TTL (10 minutes here), they turn into tombstones. Our table defines that tombstones can be purged 1 minute after they were created. If all rows are created with the same TTL, SSTables will get 100% droppable tombstones eventually and perform full SSTable deletion instead of purging tombstones through compaction.
We can observe that the oldest SSTables were removed after rows and tombstones expired :
Ven 8 jul 2016 08:07:27 CEST
-rw-r--r-- 1 adejanovski staff 220425 8 jul 07:58 twcs-twcs-ka-1587-Data.db
-rw-r--r-- 1 adejanovski staff 199402 8 jul 07:59 twcs-twcs-ka-1599-Data.db
-rw-r--r-- 1 adejanovski staff 222336 8 jul 08:00 twcs-twcs-ka-1612-Data.db
-rw-r--r-- 1 adejanovski staff 198747 8 jul 08:01 twcs-twcs-ka-1624-Data.db
-rw-r--r-- 1 adejanovski staff 203138 8 jul 08:02 twcs-twcs-ka-1636-Data.db
-rw-r--r-- 1 adejanovski staff 219365 8 jul 08:03 twcs-twcs-ka-1649-Data.db
-rw-r--r-- 1 adejanovski staff 197051 8 jul 08:04 twcs-twcs-ka-1661-Data.db
-rw-r--r-- 1 adejanovski staff 218333 8 jul 08:05 twcs-twcs-ka-1674-Data.db
-rw-r--r-- 1 adejanovski staff 203781 8 jul 08:06 twcs-twcs-ka-1686-Data.db
-rw-r--r-- 1 adejanovski staff 200753 8 jul 08:07 twcs-twcs-ka-1698-Data.db
-rw-r--r-- 1 adejanovski staff 88457 8 jul 08:07 twcs-twcs-ka-1703-Data.db
When a bucket exits the current time window, it undergoes a major compaction to eventually get a single SSTable per bucket. That major compaction will always be performed if the current bucket is up to date on compactions. This is a major improvement over the DTCS max_sstable_age_days parameter that prevented SSTables reaching it to be compacted, leaving thousands of SSTables per Cassandra table on high throughput clusters. The problem with keeping a lot of uncompacted SSTables is that Cassandra needs to check which ones contain the required partition for each read. While bloom filters are a very efficient way of performing that check, having to perform this operation thousands of times versus tens makes a significant difference in the quest for low latency reads.
It is advised to aim for less than 50 buckets per table based on the insertion TTL. Our twcs.twcs table should then have a TTL that doesn’t exceed 50 minutes, while a 90 days TTL would make us pick 3 days buckets :
CREATE TABLE twcs.twcs_90_days_ttl (
id int,
value int,
text_value text,
PRIMARY KEY (id, value)
) WITH CLUSTERING ORDER BY (value ASC)
AND bloom_filter_fp_chance = 0.01
AND caching = '{"keys":"ALL", "rows_per_partition":"NONE"}'
AND comment = ''
AND gc_grace_seconds = 60
AND default_time_to_live = 7776000
AND compaction = {'compaction_window_size': '3',
'compaction_window_unit': 'DAYS',
'class': 'org.apache.cassandra.db.compaction.TimeWindowCompactionStrategy'}
Note that compaction_window_size takes any value of “MINUTES”, “HOURS” or “DAYS” to make it simple to reason about. Which bucket an SSTable belongs to is determined by its highest timestamp.
This setup would give us the following guarantees :
- Data older than 3 days stops being compacted, lowering I/O consumption
- Queries targeting rows within a 3 days time range will mostly hit a limited number of SSTables in case compaction is up to date
- Using TTL inserts, tombstones get purged by file deletion (in this case, shortly after 90 days and 1 minute after the original write)
- Data sent out of their original time window through hints or repairs are compacted with SSTables of the current window only, preventing write amplification
- Maximum compaction overhead on disk is 50% of the last created bucket
- Disk space usage growth is easily predictable
A side effect is that out-of-window repairs will fragment partitions into several buckets that will never be compacted together. This is a deliberate tradeoff to avoid the write amplification problem.
Use case
TWCS is a compaction strategy mostly fit for time series, just as its ancestor DTCS was. More broadly, it is designed for write-once immutable rows (clustering keys), with a TTL.
It is not designed for rows updated or explicitly deleted over many time windows, as this would keep rows from being compacted together once they crossed the time window threshold.
Tuning compaction properties
As TWCS relies on STCS, standard Size Tiered Compaction properties are available for compaction tuning.
Tuning tombstone purge
If a more aggressive strategy is needed to reclaim disk space and purge tombstones, unchecked_tombstone_compaction can be set to true.
If TTL is below one day, tombstone_compaction_interval should be set to match : TTL + gc_grace_seconds
Considering TWCS should be used with immutable TTLed rows only, it is safe to use a low gc_grace_seconds value.
Major compaction
TWCS can run on-demand major compactions through the nodetool compact command.
The major compaction falls back to STCS and compacts together all SSTables of a table, even if they belong in different time buckets.
Switching an existing table to TWCS
Switching a table to TWCS is done through the ALTER TABLE command :
ALTER TABLE my_stcs_table
WITH compaction = {'compaction_window_size': '1',
'compaction_window_unit': 'DAYS',
'class': org.apache.cassandra.db.compaction.TimeWindowCompactionStrategy'};
After issuing the ALTER statement, SSTables will get grouped by bucket based on their maximum timestamp, and size tiered compacted inside each bucket.
Here’s a list of SSTables for a table using Leveled Compaction Strategy along with their maximum insertion timestamp :
macbook-pro:my_twcs_table-3cdb91f0474f11e6b3e6ad195cb1e991 adejanovski$ for f in *Data.db; do ls -lrt $f;echo 'Max timestamp : ' && date -r $(sstablemetadata $f | grep Maximum\ time | cut -d" " -f3| cut -c 1-10) '+%m/%d/%Y %H:%M:%S'; done
-rw-r--r-- 1 adejanovski staff 1064128 11 jul 14:42 mb-5702-big-Data.db
Max timestamp :
07/11/2016 14:41:53
-rw-r--r-- 1 adejanovski staff 1069630 11 jul 14:43 mb-5846-big-Data.db
Max timestamp :
07/11/2016 14:43:18
-rw-r--r-- 1 adejanovski staff 1074573 11 jul 14:44 mb-5989-big-Data.db
Max timestamp :
07/11/2016 14:44:43
-rw-r--r-- 1 adejanovski staff 1073635 11 jul 14:44 mb-5991-big-Data.db
Max timestamp :
07/11/2016 14:44:43
-rw-r--r-- 1 adejanovski staff 1048760 11 jul 14:46 mb-6134-big-Data.db
Max timestamp :
07/11/2016 14:46:08
-rw-r--r-- 1 adejanovski staff 29907 11 jul 14:46 mb-6135-big-Data.db
Max timestamp :
07/11/2016 14:46:08
-rw-r--r-- 1 adejanovski staff 1052466 11 jul 14:47 mb-6277-big-Data.db
Max timestamp :
07/11/2016 14:47:34
-rw-r--r-- 1 adejanovski staff 1056004 11 jul 14:49 mb-6421-big-Data.db
Max timestamp :
07/11/2016 14:48:58
-rw-r--r-- 1 adejanovski staff 1071221 11 jul 14:57 mb-6542-big-Data.db
Max timestamp :
07/11/2016 14:56:55
-rw-r--r-- 1 adejanovski staff 1049921 11 jul 14:57 mb-6543-big-Data.db
Max timestamp :
07/11/2016 14:56:55
-rw-r--r-- 1 adejanovski staff 1057914 11 jul 14:57 mb-6546-big-Data.db
Max timestamp :
07/11/2016 14:56:55
-rw-r--r-- 1 adejanovski staff 1057416 11 jul 14:57 mb-6548-big-Data.db
Max timestamp :
07/11/2016 14:56:55
-rw-r--r-- 1 adejanovski staff 1057610 11 jul 14:57 mb-6549-big-Data.db
Max timestamp :
07/11/2016 14:56:55
-rw-r--r-- 1 adejanovski staff 1054329 11 jul 14:57 mb-6550-big-Data.db
Max timestamp :
07/11/2016 14:56:55
-rw-r--r-- 1 adejanovski staff 1056487 11 jul 14:57 mb-6551-big-Data.db
Max timestamp :
07/11/2016 14:56:55
-rw-r--r-- 1 adejanovski staff 1064145 11 jul 14:57 mb-6553-big-Data.db
Max timestamp :
07/11/2016 14:56:55
-rw-r--r-- 1 adejanovski staff 1057628 11 jul 14:57 mb-6554-big-Data.db
Max timestamp :
07/11/2016 14:56:55
-rw-r--r-- 1 adejanovski staff 702415 11 jul 14:57 mb-6556-big-Data.db
Max timestamp :
07/11/2016 14:56:55
-rw-r--r-- 1 adejanovski staff 1056318 11 jul 14:57 mb-6557-big-Data.db
Max timestamp :
07/11/2016 14:56:55
-rw-r--r-- 1 adejanovski staff 577786 11 jul 14:57 mb-6629-big-Data.db
Max timestamp :
07/11/2016 14:57:47
Shortly after switching compaction strategy to TWCS with 1 minutes buckets, the directory has the following content :
macbook-pro:my_twcs_table-3cdb91f0474f11e6b3e6ad195cb1e991 adejanovski$ for f in *Data.db; do ls -lrt $f; echo 'Max timestamp :' && date -r $(sstablemetadata $f | grep Maximum\ time | cut -d" " -f3| cut -c 1-10) '+%m/%d/%Y %H:%M:%S'; done
-rw-r--r-- 1 adejanovski staff 1064128 11 jul 14:42 mb-5702-big-Data.db
Max timestamp :
07/11/2016 14:41:53
-rw-r--r-- 1 adejanovski staff 1069630 11 jul 14:43 mb-5846-big-Data.db
Max timestamp :
07/11/2016 14:43:18
-rw-r--r-- 1 adejanovski staff 1052466 11 jul 14:47 mb-6277-big-Data.db
Max timestamp :
07/11/2016 14:47:34
-rw-r--r-- 1 adejanovski staff 1056004 11 jul 14:49 mb-6421-big-Data.db
Max timestamp :
07/11/2016 14:48:58
-rw-r--r-- 1 adejanovski staff 577786 11 jul 14:57 mb-6629-big-Data.db
Max timestamp :
07/11/2016 14:57:47
-rw-r--r-- 1 adejanovski staff 12654 11 jul 14:59 mb-6630-big-Data.db
Max timestamp :
07/11/2016 14:57:48
-rw-r--r-- 1 adejanovski staff 11276126 11 jul 14:59 mb-6631-big-Data.db
Max timestamp :
07/11/2016 14:56:55
-rw-r--r-- 1 adejanovski staff 1078628 11 jul 14:59 mb-6632-big-Data.db
Max timestamp :
07/11/2016 14:46:08
-rw-r--r-- 1 adejanovski staff 2148408 11 jul 14:59 mb-6633-big-Data.db
Max timestamp :
07/11/2016 14:44:43
We can observe that eligible SSTables were recompacted together according to TWCS and STCS rules.
There is not much to prepare when switching to TWCS, and one can expect low activity when coming from STCS as the two strategies have a similar behavior. Switching from LCS can create more activity, but rest assured that the current time window has a higher priority and will thus occupy all the compaction slots if needed. SSTables belonging to older buckets will get compacted only if there is not enough to be done in the current bucket.
Bootstrapping
Bootstrapping follows the same path, as all SSTables within each bucket will get compacted together.
This avoids one of DTCS drawback that did not compact streamed SSTables that had reached max_sstable_age_days.
Hints and repairs
To avoid write amplification, TWCS uses the maximum timestamp of SSTables to group files into time windowed buckets (unlike DTCS which uses the minimum timestamp). One of the caveats of that choice is that hints, read repair and anti-entropy repair can mix data that should belong to old buckets into new ones. This has the following drawbacks :
- Some tombstones might not get reclaimed until the whole newly created SSTable expires
- Reads on specific repaired partitions could have higher latencies as they may hit more buckets/SSTables
The tombstone caveat can be mitigated by having a tuned single SSTable compaction strategy.
Timestamp overlaps
Using the sstablemetadata tool and some (ugly) pipe-grep-awk-whatever command, we can get interesting outputs on our SSTables :
for f in *Data.db; do meta=$(sudo sstablemetadata $f); echo -e "Max:" $(date --date=@$(echo "$meta" | grep Maximum\ time | cut -d" " -f3| cut -c 1-10) '+%m/%d/%Y') "Min:" $(date --date=@$(echo "$meta" | grep Minimum\ time | cut -d" " -f3| cut -c 1-10) '+%m/%d/%Y') $(echo "$meta" | grep droppable) ' \t ' $(ls -lh $f | awk '{print $5" "$6" "$7" "$8" "$9}'); done | sort
The above will list all SSTables sorted by maximum timestamp of contained data and give us both the minimum timestamp and estimated droppable tombstone ratio.
Here’s the output of this command on a real world production cluster using TWCS :
Max: 10/04/2016 Min: 10/03/2016 Estimated droppable tombstones: 0.9490505651577649 31G Oct 31 05:30 myks-mytable-ka-232963-Data.db
Max: 10/05/2016 Min: 10/04/2016 Estimated droppable tombstones: 0.9560987002875797 38G Oct 31 10:03 myks-mytable-ka-233129-Data.db
Max: 10/06/2016 Min: 10/04/2016 Estimated droppable tombstones: 0.9481618753615573 36G Oct 30 21:05 myks-mytable-ka-232429-Data.db
Max: 10/07/2016 Min: 10/04/2016 Estimated droppable tombstones: 0.9521717448567388 38G Oct 30 18:26 myks-mytable-ka-232273-Data.db
Max: 10/08/2016 Min: 10/03/2016 Estimated droppable tombstones: 0.95585602260063 38G Oct 30 13:16 myks-mytable-ka-232101-Data.db
Max: 10/09/2016 Min: 10/03/2016 Estimated droppable tombstones: 0.949381410220861 33G Oct 30 09:00 myks-mytable-ka-232018-Data.db
Max: 10/10/2016 Min: 10/03/2016 Estimated droppable tombstones: 0.9559645399027142 39G Oct 30 07:32 myks-mytable-ka-231925-Data.db
Max: 10/11/2016 Min: 10/04/2016 Estimated droppable tombstones: 0.950634006146064 35G Oct 31 07:11 myks-mytable-ka-233032-Data.db
Max: 10/12/2016 Min: 10/03/2016 Estimated droppable tombstones: 0.9486612959756701 35G Oct 31 02:20 myks-mytable-ka-232740-Data.db
Max: 10/13/2016 Min: 10/03/2016 Estimated droppable tombstones: 0.9554470308141092 38G Oct 30 22:34 myks-mytable-ka-232493-Data.db
Max: 10/14/2016 Min: 10/03/2016 Estimated droppable tombstones: 0.949693885678604 36G Oct 30 18:20 myks-mytable-ka-232277-Data.db
Max: 10/15/2016 Min: 10/03/2016 Estimated droppable tombstones: 0.9557383456090225 37G Oct 30 13:33 myks-mytable-ka-232100-Data.db
Max: 10/16/2016 Min: 10/05/2016 Estimated droppable tombstones: 0.9504753169563435 81G Oct 17 10:45 myks-mytable-ka-217230-Data.db
Max: 10/17/2016 Min: 10/04/2016 Estimated droppable tombstones: 0.4789361839518767 85G Oct 18 13:19 myks-mytable-ka-218505-Data.db
Max: 10/18/2016 Min: 10/04/2016 Estimated droppable tombstones: 0.26920166792514394 84G Oct 19 05:44 myks-mytable-ka-219298-Data.db
Max: 10/19/2016 Min: 10/18/2016 Estimated droppable tombstones: 0.2398632806404871 82G Oct 20 08:53 myks-mytable-ka-220668-Data.db
Max: 10/20/2016 Min: 10/19/2016 Estimated droppable tombstones: 0.2345777170103667 81G Oct 21 09:43 myks-mytable-ka-221815-Data.db
Max: 10/21/2016 Min: 10/20/2016 Estimated droppable tombstones: 0.23166383913432712 83G Oct 22 09:56 myks-mytable-ka-222971-Data.db
Max: 10/22/2016 Min: 10/21/2016 Estimated droppable tombstones: 0.22872970980627125 81G Oct 23 09:59 myks-mytable-ka-224097-Data.db
Max: 10/23/2016 Min: 10/22/2016 Estimated droppable tombstones: 0.26338126235319065 81G Oct 24 06:17 myks-mytable-ka-224961-Data.db
Max: 10/24/2016 Min: 10/23/2016 Estimated droppable tombstones: 0.22151053801117235 82G Oct 25 11:28 myks-mytable-ka-226389-Data.db
Max: 10/25/2016 Min: 10/24/2016 Estimated droppable tombstones: 0.22783088210413793 80G Oct 26 09:56 myks-mytable-ka-227462-Data.db
Max: 10/26/2016 Min: 10/25/2016 Estimated droppable tombstones: 0.21954613750782576 80G Oct 27 11:32 myks-mytable-ka-228663-Data.db
Max: 10/27/2016 Min: 10/26/2016 Estimated droppable tombstones: 0.21810718139671728 81G Oct 28 11:20 myks-mytable-ka-229793-Data.db
Max: 10/28/2016 Min: 10/27/2016 Estimated droppable tombstones: 0.2263842889481549 83G Oct 29 09:47 myks-mytable-ka-230858-Data.db
Max: 10/29/2016 Min: 10/28/2016 Estimated droppable tombstones: 0.21774533904969468 82G Oct 30 11:32 myks-mytable-ka-232030-Data.db
Max: 10/30/2016 Min: 10/29/2016 Estimated droppable tombstones: 0.21695190527031055 81G Oct 31 11:06 myks-mytable-ka-233114-Data.db
Max: 10/31/2016 Min: 10/30/2016 Estimated droppable tombstones: 0.2590062225892238 6.4G Oct 31 02:00 myks-mytable-ka-232914-Data.db
Max: 10/31/2016 Min: 10/31/2016 Estimated droppable tombstones: 0.2573703764996242 119M Oct 31 10:53 myks-mytable-ka-233223-Data.db
Max: 10/31/2016 Min: 10/31/2016 Estimated droppable tombstones: 0.25738010877995654 82M Oct 31 11:03 myks-mytable-ka-233227-Data.db
Max: 10/31/2016 Min: 10/31/2016 Estimated droppable tombstones: 0.25771639853000644 1.8G Oct 31 10:39 myks-mytable-ka-233213-Data.db
SSTables with more than 0.9 droppable tombstones are actually fully droppable and tombstones are past gc_grace_seconds, but still many are yet to be deleted.
Looking closely at timestamps, we can see that the oldest SSTable has a minimum timestamp on 10/03, which overlaps with SSTable myks-mytable-ka-232101-Data.db, which overlaps with SSTables myks-mytable-ka-218505-Data.db and myks-mytable-ka-219298-Data.db among others. Those last two SSTables are not yet fully expired, which prevents dropping all other SSTables that overlap with them because of safety checks that Apache Cassandra performs to avoid deleted data from reappearing.
In this particular case, we will have to wait for 2 more days until both overlapping SSTables fully expire, to reclaim more than 470 GB of tombstones.
Deletions
TWCS is no fit for workload that perform deletes on non TTLed data. Consider that SSTables from different time windows will never be compacted together, so data inserted on day 1 and deleted on day 2 will have the tombstone and the shadowed cells living in different time windows. Unless a major compaction is performed (which shouldn’t), and while the deletion will seem effective when running queries, space will never be reclaimed on disk.
Deletes can be performed on TTLed data if needed, but the partition will then exist in different time windows, which will postpone actual deletion from disk until both time windows fully expire.
Summary
DTCS failed to deliver the expected results but it fathered TWCS and allowed the birth of a compaction strategy that is both easy to reason about and permits great predictability in both disk usage and compaction load.
TWCS is a perfect fit for time series but is suitable for all tables receiving immutable “TTLed” inserts.
It is advised to disable read repair on TWCS tables, and use an agressive tombstone purging strategy as digest mismatches during reads will still trigger read repairs. Those will inevitably create overlaps over several time windows, preventing fully expired SSTables from being deleted until overlapping SSTables reach 100% of expired rows.
Real world switch from DTCS to TWCS on several clusters of our customers have shown improvements in CPU usage, reduced I/O, read latencies and tombstone eviction, making TWCS a compaction strategy that should definitely be considered for applicable loads.
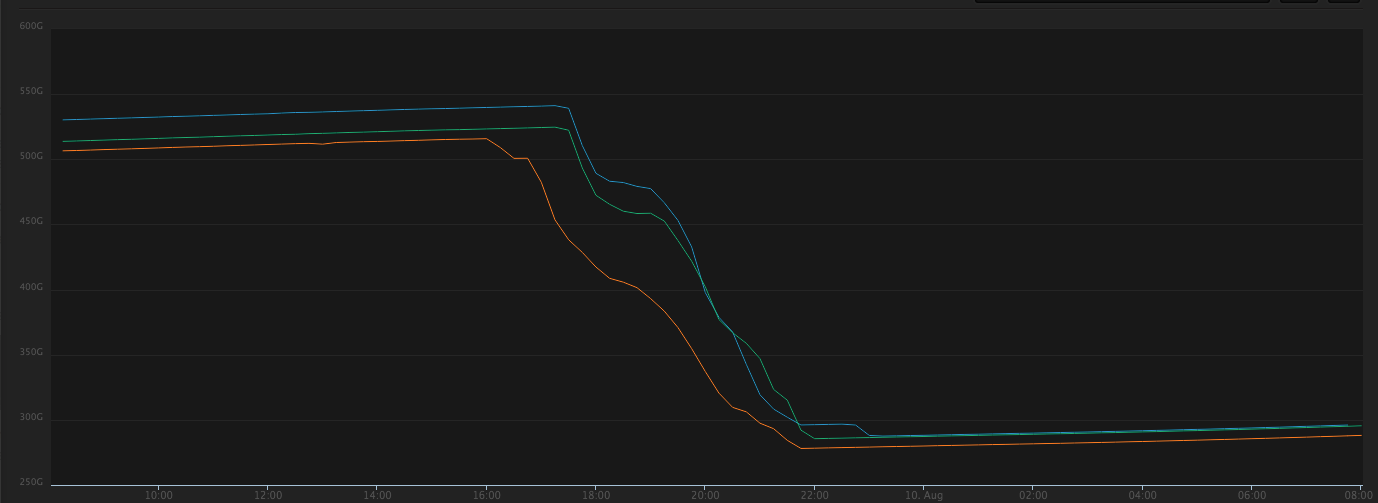
Here’s an example where we’ve managed to reduce the number of SSTables from more than 1000 to ~50 in a few hours and reclaim 100s GB of disk space :
In our next blog post, Jon Haddad will show us how to install TWCS on older versions of Cassandra and how to switch tables to it, node by node, in a rolling fashion through some JMX voodoo tricks.