![]()
Alain Rodriguez
About Deletes and Tombstones in Cassandra
Deleting distributed and replicated data from a system such as Apache Cassandra is far trickier than in a relational database. The process of deletion becomes more interesting when we consider that Cassandra stores its data in immutable files on disk. In such a system, to record the fact that a delete happened, a special value called a “tombstone” needs to be written as an indicator that previous values are to be considered deleted. Though this may seem quite unusual and/or counter-intuitive (particularly when you realize that a delete actually takes up space on disk), we’ll use this blog post to explain what is actually happening along side examples that you can follow on your own.
Cassandra: Some Availability and Consistency Considerations
Before we dive into details, we should take a quick step back for review to see how Cassandra works as a distributed system, particulalry in the context of availability and consistency. This is necessary to correctly explain distributed deletes and outline the potential issues which we will cover later on.
Availability: To ensure availability Cassandra replicates data. Specifically, multiple copies of each piece of data is stored on distinct nodes according to the Replication Factor (RF). The RF defines the number of copies to keep in each datacenter per keyspace. Depending on the configuration, copies can also spread evenly over distinct racks, as long as there are enough racks available and the configured snitch and topology strategy can take them into account. With such an approach, when any node (or rack - again depending on configuration) goes down, data can still be read from other replicas.
Consistency: To ensure reading data with a strong consistency, we must respect the following rule:
CL.READ = Consistency Level (CL) used for reads. Basically the number of nodes that will have to acknowledge the read for Cassandra to consider it successful.
CL.WRITE = CL used for writes.
RF = Replication Factor
CL.READ + CL.WRITE > RF
This way we are sure to read from at least one of the nodes to which the data was written.
Common use case: Let’s consider the following common settings.
RF = 3
CL.READ = QUORUM = RF/2 + 1 = 2
CL.WRITE = QUORUM = RF/2 + 1 = 2
CL.READ + CL.WRITE > RF --> 4 > 3
With this configuration, we have high availability as there is no Single Point Of Failure (SPOF). We can afford losing a node because we are sure that any read will fetch the written data at least on one node and then apply the Last Write Wins (LWW) algorithm to choose which node is holding the correct data for this read.
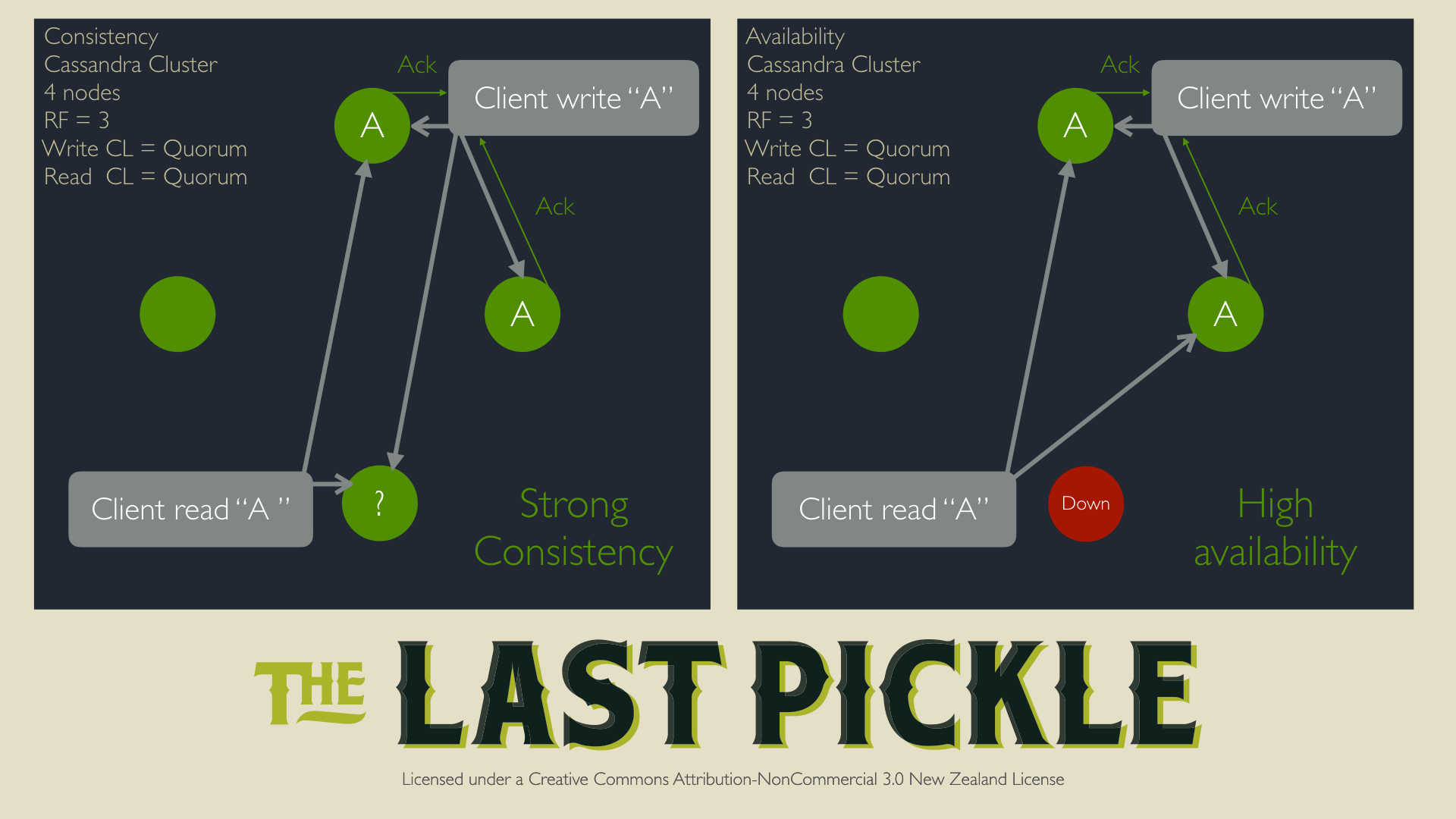
With this configuration and behavior in mind, let’s walk through some examples of performing deletes.
The problem with distributed deletes
Considering the case above, that is supposed to be strongly consistent. Let’s forget about tombstones for a second and consider the case where Cassandra was not using tombstones to delete data. Let’s consider a successful delete that fails on one node (out of three, RF=3). This delete would still be considered successful (two nodes acknowledged the delete, using CL.QUORUM). The next read involving that node will be an ambiguous read since there is no way to determine what is correct: return an empty response or return the data? Cassandra would always consider that returning the data is the correct thing to do, so deletes would often lead to reappearing data, called “zombie” or “ghost” and their behavior would be unpredictable.
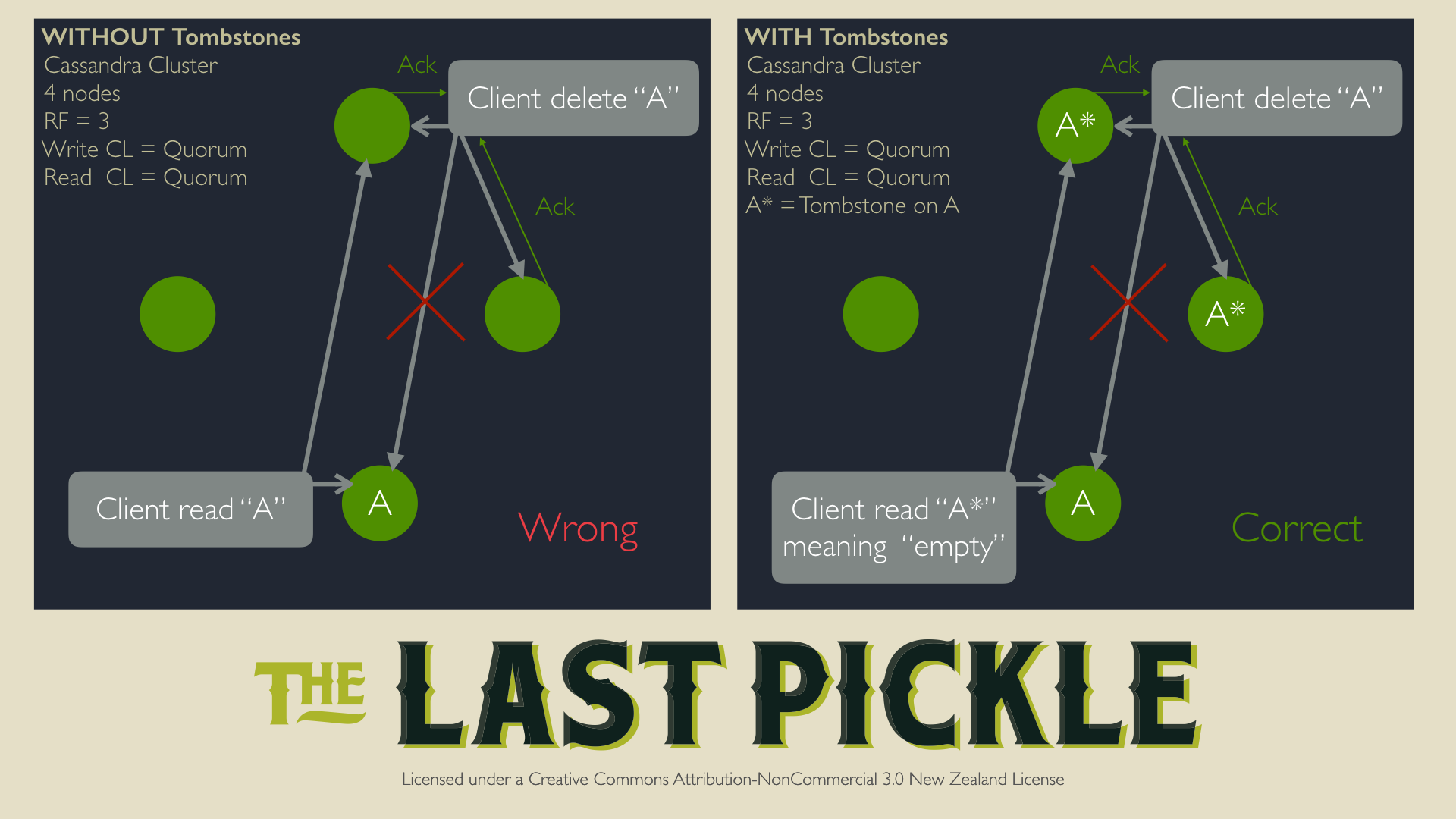
Note: This issue has not completely been solved, even with tombstones, but rather worked around as follows: as Cassandra operators we have to run a full repair of any cluster performing deletes at least once every gc_grace_seconds. See the “Tombstones drop” section below.
Deletes from the Perspective of a Cassandra Node
As mentioned previously, tombstones also address the problem of deleting data from a system which uses immutable files to store data.
One of the characteristics of Cassandra is that it uses a log-structured merge-tree (LSM tree), while most RDBMS use a B-tree. The best way to understand this is by remembering that Cassandra always appends data from writes with reads taking care of merging the row fragments together, picking the latest version of each column to return.
Another property of LSM trees is that data is written in immutable files (called SSTables in Cassandra). As discussed initially, it is then obvious that through such a system, deletes can only be done via a special kind of write. Reads will fetch the tombstone and not consider any data pre-dating the tombstone’s timestamp.
Tombstones to the rescue
In the context of Cassandra, a tombstone is specific data stored alongside standard data. A delete does nothing more than insert a tombstone. When Cassandra reads the data it will merge all the shards of the requested rows from the memtable and the SSTables. It then applies a Last Write Wins (LWW) algorithm to choose what is the correct data, no matter if it is a standard value or a tombstone.
Example:
Let’s consider the following example on a Cassandra 3.7 cluster with 3 nodes (using ccm).
CREATE KEYSPACE tlp_lab WITH replication = {'class': 'NetworkTopologyStrategy', 'datacenter1' : 3};
CREATE TABLE tlp_lab.tombstones (fruit text, date text, crates set<int>, PRIMARY KEY (fruit, date));
And add some data, to have the fruit’s crates number every day, so we easily find them:
INSERT INTO tlp_lab.tombstones (fruit, date, crates) VALUES ('apple', '20160616', {1,2,3,4,5});
INSERT INTO tlp_lab.tombstones (fruit, date, crates) VALUES ('apple', '20160617', {1,2,3});
INSERT INTO tlp_lab.tombstones (fruit, date, crates) VALUES ('pickles', '20160616', {6,7,8}) USING TTL 2592000;
Here is the data that was just stored.
alain$ echo "SELECT * FROM tlp_lab.tombstones LIMIT 100;" | cqlsh
fruit | date | crates
---------+----------+-----------------
apple | 20160616 | {1, 2, 3, 4, 5}
apple | 20160617 | {1, 2, 3}
pickles | 20160616 | {6, 7, 8}
Now we need to manually flush the data (i.e. write a new SSTable to the disk and free the memory), as a tombstone in memory, more precisely in the memtable, will overwrite any existing values in the memtable, as this space unlike SSTables on disk is mutable.
nodetool -p 7100 flush
We can now see the data on disk:
alain$ ll /Users/alain/.ccm/Cassa-3.7/node1/data/tlp_lab/tombstones-c379952033d311e6aa4261d6a7221ccb/
total 72
drwxr-xr-x 11 alain staff 374 Jun 16 20:53 .
drwxr-xr-x 3 alain staff 102 Jun 16 20:25 ..
drwxr-xr-x 2 alain staff 68 Jun 16 17:05 backups
-rw-r--r-- 1 alain staff 43 Jun 16 20:53 mb-5-big-CompressionInfo.db
-rw-r--r-- 1 alain staff 127 Jun 16 20:53 mb-5-big-Data.db
-rw-r--r-- 1 alain staff 10 Jun 16 20:53 mb-5-big-Digest.crc32
-rw-r--r-- 1 alain staff 16 Jun 16 20:53 mb-5-big-Filter.db
-rw-r--r-- 1 alain staff 20 Jun 16 20:53 mb-5-big-Index.db
-rw-r--r-- 1 alain staff 4740 Jun 16 20:53 mb-5-big-Statistics.db
-rw-r--r-- 1 alain staff 61 Jun 16 20:53 mb-5-big-Summary.db
-rw-r--r-- 1 alain staff 92 Jun 16 20:53 mb-5-big-TOC.txt
To have a human readable format of the SSTable we will transform it using the SSTabledump tool:
alain$ SSTabledump /Users/alain/.ccm/Cassa-3.7/node1/data/tlp_lab/tombstones-c379952033d311e6aa4261d6a7221ccb/mb-5-big-Data.db
[
{
"partition" : {
"key" : [ "apple" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 19,
"clustering" : [ "20160616" ],
"liveness_info" : { "tstamp" : "2016-06-16T18:52:41.900451Z" },
"cells" : [
{ "name" : "crates", "deletion_info" : { "marked_deleted" : "2016-06-16T18:52:41.900450Z", "local_delete_time" : "2016-06-16T18:52:41Z" } },
{ "name" : "crates", "path" : [ "1" ], "value" : "" },
{ "name" : "crates", "path" : [ "2" ], "value" : "" },
{ "name" : "crates", "path" : [ "3" ], "value" : "" },
{ "name" : "crates", "path" : [ "4" ], "value" : "" },
{ "name" : "crates", "path" : [ "5" ], "value" : "" }
]
},
{
"type" : "row",
"position" : 66,
"clustering" : [ "20160617" ],
"liveness_info" : { "tstamp" : "2016-06-16T18:52:41.902093Z" },
"cells" : [
{ "name" : "crates", "deletion_info" : { "marked_deleted" : "2016-06-16T18:52:41.902092Z", "local_delete_time" : "2016-06-16T18:52:41Z" } },
{ "name" : "crates", "path" : [ "1" ], "value" : "" },
{ "name" : "crates", "path" : [ "2" ], "value" : "" },
{ "name" : "crates", "path" : [ "3" ], "value" : "" }
]
}
]
},
{
"partition" : {
"key" : [ "pickles" ],
"position" : 104
},
"rows" : [
{
"type" : "row",
"position" : 125,
"clustering" : [ "20160616" ],
"liveness_info" : { "tstamp" : "2016-06-16T18:52:41.903751Z", "ttl" : 2592000, "expires_at" : "2016-07-16T18:52:41Z", "expired" : false },
"cells" : [
{ "name" : "crates", "deletion_info" : { "marked_deleted" : "2016-06-16T18:52:41.903750Z", "local_delete_time" : "2016-06-16T18:52:41Z" } },
{ "name" : "crates", "path" : [ "6" ], "value" : "" },
{ "name" : "crates", "path" : [ "7" ], "value" : "" },
{ "name" : "crates", "path" : [ "8" ], "value" : "" }
]
}
]
}
]
Two partitions (3 rows, 2 sharing the same partition) are now stored on disk.
Let’s now consider distinct kinds of deletes:
Cell delete
A column from a specific row is called a “cell” in the Cassandra storage engine.
Deleting a cell from a row with:
DELETE crates FROM tlp_lab.tombstones WHERE fruit='apple' AND date ='20160617';
The crates column is showing null on the affected row:
alain$ echo "SELECT * FROM tlp_lab.tombstones LIMIT 100;" | cqlsh
fruit | date | crates
---------+----------+-----------------
apple | 20160616 | {1, 2, 3, 4, 5}
apple | 20160617 | null
pickles | 20160616 | {6, 7, 8}
(3 rows)
After flushing we get one more SSTable on disk, mb-6-big:
alain$ ll /Users/alain/.ccm/Cassa-3.7/node1/data/tlp_lab/tombstones-c379952033d311e6aa4261d6a7221ccb/
total 144
drwxr-xr-x 19 alain staff 646 Jun 16 21:12 .
drwxr-xr-x 3 alain staff 102 Jun 16 20:25 ..
drwxr-xr-x 2 alain staff 68 Jun 16 17:05 backups
-rw-r--r-- 1 alain staff 43 Jun 16 20:53 mb-5-big-CompressionInfo.db
-rw-r--r-- 1 alain staff 127 Jun 16 20:53 mb-5-big-Data.db
-rw-r--r-- 1 alain staff 10 Jun 16 20:53 mb-5-big-Digest.crc32
-rw-r--r-- 1 alain staff 16 Jun 16 20:53 mb-5-big-Filter.db
-rw-r--r-- 1 alain staff 20 Jun 16 20:53 mb-5-big-Index.db
-rw-r--r-- 1 alain staff 4740 Jun 16 20:53 mb-5-big-Statistics.db
-rw-r--r-- 1 alain staff 61 Jun 16 20:53 mb-5-big-Summary.db
-rw-r--r-- 1 alain staff 92 Jun 16 20:53 mb-5-big-TOC.txt
-rw-r--r-- 1 alain staff 43 Jun 16 21:12 mb-6-big-CompressionInfo.db
-rw-r--r-- 1 alain staff 43 Jun 16 21:12 mb-6-big-Data.db
-rw-r--r-- 1 alain staff 10 Jun 16 21:12 mb-6-big-Digest.crc32
-rw-r--r-- 1 alain staff 16 Jun 16 21:12 mb-6-big-Filter.db
-rw-r--r-- 1 alain staff 9 Jun 16 21:12 mb-6-big-Index.db
-rw-r--r-- 1 alain staff 4701 Jun 16 21:12 mb-6-big-Statistics.db
-rw-r--r-- 1 alain staff 59 Jun 16 21:12 mb-6-big-Summary.db
-rw-r--r-- 1 alain staff 92 Jun 16 21:12 mb-6-big-TOC.txt
And here is the mb-6-big content:
alain$ SSTabledump /Users/alain/.ccm/Cassa-3.7/node1/data/tlp_lab/tombstones-c379952033d311e6aa4261d6a7221ccb/mb-6-big-Data.db
[
{
"partition" : {
"key" : [ "apple" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 19,
"clustering" : [ "20160617" ],
"cells" : [
{ "name" : "crates", "deletion_info" : { "marked_deleted" : "2016-06-16T19:10:53.267240Z", "local_delete_time" : "2016-06-16T19:10:53Z" } }
]
}
]
}
]
See how similar this tombstone deleted cell is compared to the inserted row cells? The partition, row and cell are still there except there is no liveness_info at the column level anymore. The deletion info has been updated accordingly too. This is it. This is a cell tombstone.
Row delete
Deleting a row from a partition with:
DELETE FROM tlp_lab.tombstones WHERE fruit='apple' AND date ='20160617';
The row is not showing anymore after the delete, as expected:
alain$ echo "SELECT * FROM tlp_lab.tombstones LIMIT 100;" | cqlsh
fruit | date | crates
---------+----------+-----------------
apple | 20160616 | {1, 2, 3, 4, 5}
pickles | 20160616 | {6, 7, 8}
(2 rows)
After flushing there is one more SSTable on disk, ‘mb-7-big’ which looks as follow.
alain$ SSTabledump /Users/alain/.ccm/Cassa-3.7/node1/data/tlp_lab/tombstones-c379952033d311e6aa4261d6a7221ccb/mb-7-big-Data.db
[
{
"partition" : {
"key" : [ "apple" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 19,
"clustering" : [ "20160617" ],
"deletion_info" : { "marked_deleted" : "2016-06-16T19:31:41.142454Z", "local_delete_time" : "2016-06-16T19:31:41Z" },
"cells" : [ ]
}
]
}
]
Take a second to see how the cells (or columns) value is an empty array. A row tombstone is a row with no liveness_info and no cells. Deletion time is present at the row level as expected.
Range delete
Deleting a range (ie many rows) from a single partition with:
DELETE FROM tlp_lab.tombstones WHERE fruit='apple' AND date > '20160615';
The partition is no longer returned as it has no rows anymore. If we had older data than 20160616, the partition and remaining rows would show up:
echo "SELECT * FROM tlp_lab.tombstones LIMIT 100;" | cqlsh
fruit | date | crates
---------+----------+-----------
pickles | 20160616 | {6, 7, 8}
(1 rows)
After flushing there is one more SSTable on disk, ‘mb-8-big’ with the following content:
alain$ SSTabledump /Users/alain/.ccm/Cassa-3.7/node1/data/tlp_lab/tombstones-c379952033d311e6aa4261d6a7221ccb/mb-8-big-Data.db
[
{
"partition" : {
"key" : [ "apple" ],
"position" : 0
},
"rows" : [
{
"type" : "range_tombstone_bound",
"start" : {
"type" : "exclusive",
"clustering" : [ "20160615" ],
"deletion_info" : { "marked_deleted" : "2016-06-16T19:53:21.133300Z", "local_delete_time" : "2016-06-16T19:53:21Z" }
}
},
{
"type" : "range_tombstone_bound",
"end" : {
"type" : "inclusive",
"deletion_info" : { "marked_deleted" : "2016-06-16T19:53:21.133300Z", "local_delete_time" : "2016-06-16T19:53:21Z" }
}
}
]
}
]
As we can see, we now have a new special insert, which is not from row type but range_tombstone_bound instead. With a start and an end: from the clustering key 20160615 excluded to the end (no clustering specified). Those entries with the range_tombstone_bound type are nested in the apple partition as expected. So removing an entire range is quite efficient from a disk space perspective, we do not write an information per cell, we just store delete boundaries.
Partition delete
Deleting an entire partition with:
DELETE FROM tlp_lab.tombstones WHERE fruit='pickles';
The partition, and all its nested rows are not showing anymore after the delete, as expected. The table is now empty:
alain$ echo "SELECT * FROM tlp_lab.tombstones LIMIT 100;" | cqlsh
fruit | date | crates
-------+------+--------
(0 rows)
After flushing there is one more SSTable on disk, mb-9-big with the following content:
alain$ SSTabledump /Users/alain/.ccm/Cassa-3.7/node1/data/tlp_lab/tombstones-c379952033d311e6aa4261d6a7221ccb/mb-9-big-Data.db
[
{
"partition" : {
"key" : [ "pickles" ],
"position" : 0,
"deletion_info" : { "marked_deleted" : "2016-06-17T09:38:52.550841Z", "local_delete_time" : "2016-06-17T09:38:52Z" }
}
}
]
So again, we inserted a specific marker. A tombstone for a partition is an inserted partition with a deletion_info and no rows.
Note: When using collections, range tombstones will be generated by INSERT and UPDATE operations every time you are using an entire collection, and not updating parts of it. Inserting a collection over an existing collection, rather than appending it or updating only an item in it, leads to range tombstones insert followed by the insert of the new values for the collection. This DELETE operation is hidden leading to some weird and frustrating tombstones issues.
Having a closer look at the first SSTabledump output right after the data inserts above and before any deletion, you will see that a tombstone was there already:
"cells" : [
{ "name" : "crates", "deletion_info" : { "marked_deleted" : "2016-06-16T18:52:41.900450Z", "local_delete_time" : "2016-06-16T18:52:41Z" } },
{ "name" : "crates", "path" : [ "1" ], "value" : "" },
{ "name" : "crates", "path" : [ "2" ], "value" : "" },
{ "name" : "crates", "path" : [ "3" ], "value" : "" },
{ "name" : "crates", "path" : [ "4" ], "value" : "" },
{ "name" : "crates", "path" : [ "5" ], "value" : "" }
]
From the mailing list I found out that James Ravn posted about this topic using list example, but it is true for all the collections, so I won’t go through more details, I just wanted to point this out as it can be surprising, see: http://www.jsravn.com/2015/05/13/cassandra-tombstones-collections.html#lists
Mitigating the problems generated by tombstones
Ok, so now that we understand why we use tombstones and have a general understanding of what they are, let’s look at the potential issues they can cause and what steps we can take to mitigate them.
The first obvious thing is that instead of just removing data, we store more. At some point we need to remove those tombstones to free some disk space and to limit the unnecessary volume of data being read, improving both latencies and resource utilization. As we’ll soon see, this happens through the process of compaction.
Compactions
When we read a specific row, the more SSTables we have to consult for row fragments, the slower the read becomes. Therefore, it is necessary to merge those fragments through the process of compaction in order to maintain a low read latency. This includes the removal of eligible tombstones as we want to continue to free up disk space where possible.
Compactions work by merging row fragments from multiple SSTables to remove tombstones under certain conditions. Some conditions are specified in the table’s schema and so tunable, like gc_grace_seconds, and some are due to Cassandra internals and are hard-coded in order to make sure data is durable and consistent. Making sure no younger fragments of the data are in SSTables that are not involved in the current compaction (often referred to as “overlapping SSTables”) is necessary to avoid inconsistencies as this data would reappear as soon as the tombstone is evicted, creating this “zombie” data.
Considering the example above. After all the deletes and flushes, the table folder looks like this:
alain$ ll /Users/alain/.ccm/Cassa-3.7/node1/data/tlp_lab/tombstones-c379952033d311e6aa4261d6a7221ccb/
total 360
drwxr-xr-x 43 alain staff 1462 Jun 17 11:39 .
drwxr-xr-x 3 alain staff 102 Jun 16 20:25 ..
drwxr-xr-x 2 alain staff 68 Jun 16 17:05 backups
-rw-r--r-- 1 alain staff 43 Jun 17 11:13 mb-10-big-CompressionInfo.db
-rw-r--r-- 1 alain staff 43 Jun 17 11:13 mb-10-big-Data.db
-rw-r--r-- 1 alain staff 10 Jun 17 11:13 mb-10-big-Digest.crc32
-rw-r--r-- 1 alain staff 16 Jun 17 11:13 mb-10-big-Filter.db
-rw-r--r-- 1 alain staff 9 Jun 17 11:13 mb-10-big-Index.db
-rw-r--r-- 1 alain staff 4701 Jun 17 11:13 mb-10-big-Statistics.db
-rw-r--r-- 1 alain staff 59 Jun 17 11:13 mb-10-big-Summary.db
-rw-r--r-- 1 alain staff 92 Jun 17 11:13 mb-10-big-TOC.txt
-rw-r--r-- 1 alain staff 43 Jun 17 11:33 mb-11-big-CompressionInfo.db
-rw-r--r-- 1 alain staff 53 Jun 17 11:33 mb-11-big-Data.db
-rw-r--r-- 1 alain staff 9 Jun 17 11:33 mb-11-big-Digest.crc32
-rw-r--r-- 1 alain staff 16 Jun 17 11:33 mb-11-big-Filter.db
-rw-r--r-- 1 alain staff 9 Jun 17 11:33 mb-11-big-Index.db
-rw-r--r-- 1 alain staff 4611 Jun 17 11:33 mb-11-big-Statistics.db
-rw-r--r-- 1 alain staff 59 Jun 17 11:33 mb-11-big-Summary.db
-rw-r--r-- 1 alain staff 92 Jun 17 11:33 mb-11-big-TOC.txt
-rw-r--r-- 1 alain staff 43 Jun 17 11:33 mb-12-big-CompressionInfo.db
-rw-r--r-- 1 alain staff 42 Jun 17 11:33 mb-12-big-Data.db
-rw-r--r-- 1 alain staff 10 Jun 17 11:33 mb-12-big-Digest.crc32
-rw-r--r-- 1 alain staff 16 Jun 17 11:33 mb-12-big-Filter.db
-rw-r--r-- 1 alain staff 9 Jun 17 11:33 mb-12-big-Index.db
-rw-r--r-- 1 alain staff 4611 Jun 17 11:33 mb-12-big-Statistics.db
-rw-r--r-- 1 alain staff 59 Jun 17 11:33 mb-12-big-Summary.db
-rw-r--r-- 1 alain staff 92 Jun 17 11:33 mb-12-big-TOC.txt
-rw-r--r-- 1 alain staff 43 Jun 17 11:39 mb-13-big-CompressionInfo.db
-rw-r--r-- 1 alain staff 32 Jun 17 11:39 mb-13-big-Data.db
-rw-r--r-- 1 alain staff 9 Jun 17 11:39 mb-13-big-Digest.crc32
-rw-r--r-- 1 alain staff 16 Jun 17 11:39 mb-13-big-Filter.db
-rw-r--r-- 1 alain staff 11 Jun 17 11:39 mb-13-big-Index.db
-rw-r--r-- 1 alain staff 4591 Jun 17 11:39 mb-13-big-Statistics.db
-rw-r--r-- 1 alain staff 65 Jun 17 11:39 mb-13-big-Summary.db
-rw-r--r-- 1 alain staff 92 Jun 17 11:39 mb-13-big-TOC.txt
-rw-r--r-- 1 alain staff 43 Jun 17 11:12 mb-9-big-CompressionInfo.db
-rw-r--r-- 1 alain staff 127 Jun 17 11:12 mb-9-big-Data.db
-rw-r--r-- 1 alain staff 10 Jun 17 11:12 mb-9-big-Digest.crc32
-rw-r--r-- 1 alain staff 16 Jun 17 11:12 mb-9-big-Filter.db
-rw-r--r-- 1 alain staff 20 Jun 17 11:12 mb-9-big-Index.db
-rw-r--r-- 1 alain staff 4740 Jun 17 11:12 mb-9-big-Statistics.db
-rw-r--r-- 1 alain staff 61 Jun 17 11:12 mb-9-big-Summary.db
-rw-r--r-- 1 alain staff 92 Jun 17 11:12 mb-9-big-TOC.txt
Your SSTable numbers will most likely not match with the example above, but inserts and deletes are exactly the same. We can see that this tombstones table is actually empty. Files stored on disk only contain tombstones and the entries they deleted exclusively. From the perspective of the read, there is no result:
echo "SELECT * FROM tlp_lab.tombstones LIMIT 100;" | cqlsh
fruit | date | crates
-------+------+--------
(0 rows)
At this point, let’s trigger a major compaction to merge all the SSTables. Compactions run usually better when they are automated. Disabling auto compaction and running a major compaction is rarely a good idea. It is done here for pedagogical purpose.
nodetool -p 7100 compact
Now all the SSTables have been merged into a single SSTable:
alain$ ll /Users/alain/.ccm/Cassa-3.7/node1/data/tlp_lab/tombstones-c379952033d311e6aa4261d6a7221ccb/
total 72
drwxr-xr-x 11 alain staff 374 Jun 17 14:50 .
drwxr-xr-x 3 alain staff 102 Jun 16 20:25 ..
drwxr-xr-x 2 alain staff 68 Jun 16 17:05 backups
-rw-r--r-- 1 alain staff 51 Jun 17 14:50 mb-14-big-CompressionInfo.db
-rw-r--r-- 1 alain staff 105 Jun 17 14:50 mb-14-big-Data.db
-rw-r--r-- 1 alain staff 10 Jun 17 14:50 mb-14-big-Digest.crc32
-rw-r--r-- 1 alain staff 16 Jun 17 14:50 mb-14-big-Filter.db
-rw-r--r-- 1 alain staff 20 Jun 17 14:50 mb-14-big-Index.db
-rw-r--r-- 1 alain staff 4737 Jun 17 14:50 mb-14-big-Statistics.db
-rw-r--r-- 1 alain staff 61 Jun 17 14:50 mb-14-big-Summary.db
-rw-r--r-- 1 alain staff 92 Jun 17 14:50 mb-14-big-TOC.txt
And here is the content of the SSTable, containing all the tombstones, merged into the same structure, in the same file.
alain$ SSTabledump /Users/alain/.ccm/Cassa-3.7/node1/data/tlp_lab/tombstones-c379952033d311e6aa4261d6a7221ccb/mb-14-big-Data.db
[
{
"partition" : {
"key" : [ "apple" ],
"position" : 0
},
"rows" : [
{
"type" : "range_tombstone_bound",
"start" : {
"type" : "exclusive",
"clustering" : [ "20160615" ],
"deletion_info" : { "marked_deleted" : "2016-06-17T09:14:11.697040Z", "local_delete_time" : "2016-06-17T09:14:11Z" }
}
},
{
"type" : "row",
"position" : 40,
"clustering" : [ "20160617" ],
"deletion_info" : { "marked_deleted" : "2016-06-17T09:33:56.367859Z", "local_delete_time" : "2016-06-17T09:33:56Z" },
"cells" : [ ]
},
{
"type" : "range_tombstone_bound",
"end" : {
"type" : "inclusive",
"deletion_info" : { "marked_deleted" : "2016-06-17T09:14:11.697040Z", "local_delete_time" : "2016-06-17T09:14:11Z" }
}
}
]
},
{
"partition" : {
"key" : [ "pickles" ],
"position" : 73,
"deletion_info" : { "marked_deleted" : "2016-06-17T09:38:52.550841Z", "local_delete_time" : "2016-06-17T09:38:52Z" }
}
}
]
Note that at this point tombstoned data is directly removed during the compaction. However, as previously discussed, we do still store a tombstone marker on disk, as we need to keep a record of the delete itself in order effectively communicate the delete operation to the rest of the cluster. We need not keep the actual value as that is not needed for consistency.
Tombstones drop
Cassandra will fully drop those tombstones when a compaction triggers, only after local_delete_time + gc_grace_seconds as defined on the table the data belongs to. Remember that all the nodes are supposed to have been repaired within gc_grace_seconds to ensure a correct distribution of the tombstones and prevent deleted data from reappearing as mentioned above.
This gc_grace_seconds parameters is the minimal time that tombstones will be kept on disk after data has been deleted. We need to make sure that all the replicas also received the delete and have tombstone stored to avoid having some zombie data issues. Our only way to achieve that is a full repair. After gc_grace_seconds, the tombstone will eventually be evicted and if a node missed the tombstone, we will be in the situation described above where the data can reappear. TTL are not affected as no node can have the data and miss the associated TTL, it is atomic, the same record. Any node having the data will also know when the data has to be deleted.
Also, to remove deleted data and tombstones from a disk, there are other safety rules that Cassandra code needs to follow. We need all the fragments of a row or partition to be in the same compaction for the tombstone to be removed. Considering a compaction handles files 1 to 4, if some data is on table 5, the tombstones will not be evicted, as we still need it to mark data on SSTable 5 as being deleted, or data from SSTable 5 would come back (zombie).
Those conditions sometimes make removing tombstones a very complex thing. It often causes a lot of troubles to Cassandra users. Tombstones not being removed can mean a lot of disk space used, slower reads, more work for repairs, a higher GC pressure, more resources needed, etc. When most of your SSTables for a table have a high tombstone ratio (90% of the data are tombstones), it becomes hard to read a proper value, a relevant piece of data, and the storage cost is higher. These kind of issues can even lead to running out of disk space.
A lot of use cases lead to data deletion (TTL or deletes) and it is something we need to control as Cassandra operators.
Back to our example a last time. I restarted the node a few days later (few days > 10 days, the default gc_grace_seconds). Cassandra opened the compacted SSTable we had built above mb-14-big, it get compacted right away.
MacBook-Pro:tombstones alain$ grep 'mb-14-big' /Users/alain/.ccm/Cassa-3.7/node1/logs/system.log
DEBUG [SSTableBatchOpen:1] 2016-06-28 15:56:17,947 SSTableReader.java:482 - Opening /Users/alain/.ccm/Cassa-3.7/node1/data/tlp_lab/tombstones-c379952033d311e6aa4261d6a7221ccb/mb-14-big (0.103KiB)
DEBUG [CompactionExecutor:2] 2016-06-28 15:56:18,525 CompactionTask.java:150 - Compacting (166f61c0-3d38-11e6-bfe3-e9e451310a18) [/Users/alain/.ccm/Cassa-3.7/node1/data/tlp_lab/tombstones-c379952033d311e6aa4261d6a7221ccb/mb-14-big-Data.db:level=0, ]
At this time as gc_grace_seconds has passed, the tombstones were eligible for eviction. So all the tombstones were removed and since there were no data in this table anymore, the data folder is now finally empty.
MacBook-Pro:tombstones alain$ ll /Users/alain/.ccm/Cassa-3.7/node1/data/tlp_lab/tombstones-c379952033d311e6aa4261d6a7221ccb/
total 0
drwxr-xr-x 3 alain staff 102 Jun 28 15:56 .
drwxr-xr-x 3 alain staff 102 Jun 16 20:25 ..
MacBook-Pro:tombstones alain$
If the tombstone was replicated correctly on all the replicas, we would have a fully consistent delete and no data will reappear. At this point we also free some more disk space and make it easier to read other values, even if my example is a bit silly for demonstrating this purpose as the table is now fully empty.
Monitoring tombstone ratio and expiration
It is normal to have tombstones due to the Cassandra design when deleting data or using TTLs, yet it is something we need to control.
To know the tombstone ratio of a table or to have an estimated distribution of the tombstone drop time (ie. delete timestamp) on any SSTable, use SSTablemetadata:
alain$ SSTablemetadata /Users/alain/.ccm/Cassa-3.7/node1/data/tlp_lab/tombstones-c379952033d311e6aa4261d6a7221ccb/mb-14-big-Data.db
--
Estimated droppable tombstones: 2.0
--
Estimated tombstone drop times:
1466154851: 2
1466156036: 1
1466156332: 1
--
The ratio above is probably wrong because of the specific state where I have 0 useful rows and only tombstones in this mb-14-big file, but it is usually a good indicator of the SSTable status regarding tombstones.
Also, Cassandra exposes this metric called TombstoneScannedHistogram through JMX for any table. To be clear, scope=tombstones is where the table name is specified:
org.apache.cassandra.metrics:type=Table,keyspace=tlp_lab,scope=tombstones,name=TombstoneScannedHistogram
This is something worth being plugged into a monitoring tool such as Graphite / Grafana, Datadog, New Relic, etc.
Here is a jconsole output from my example above before compaction removed tombstones:
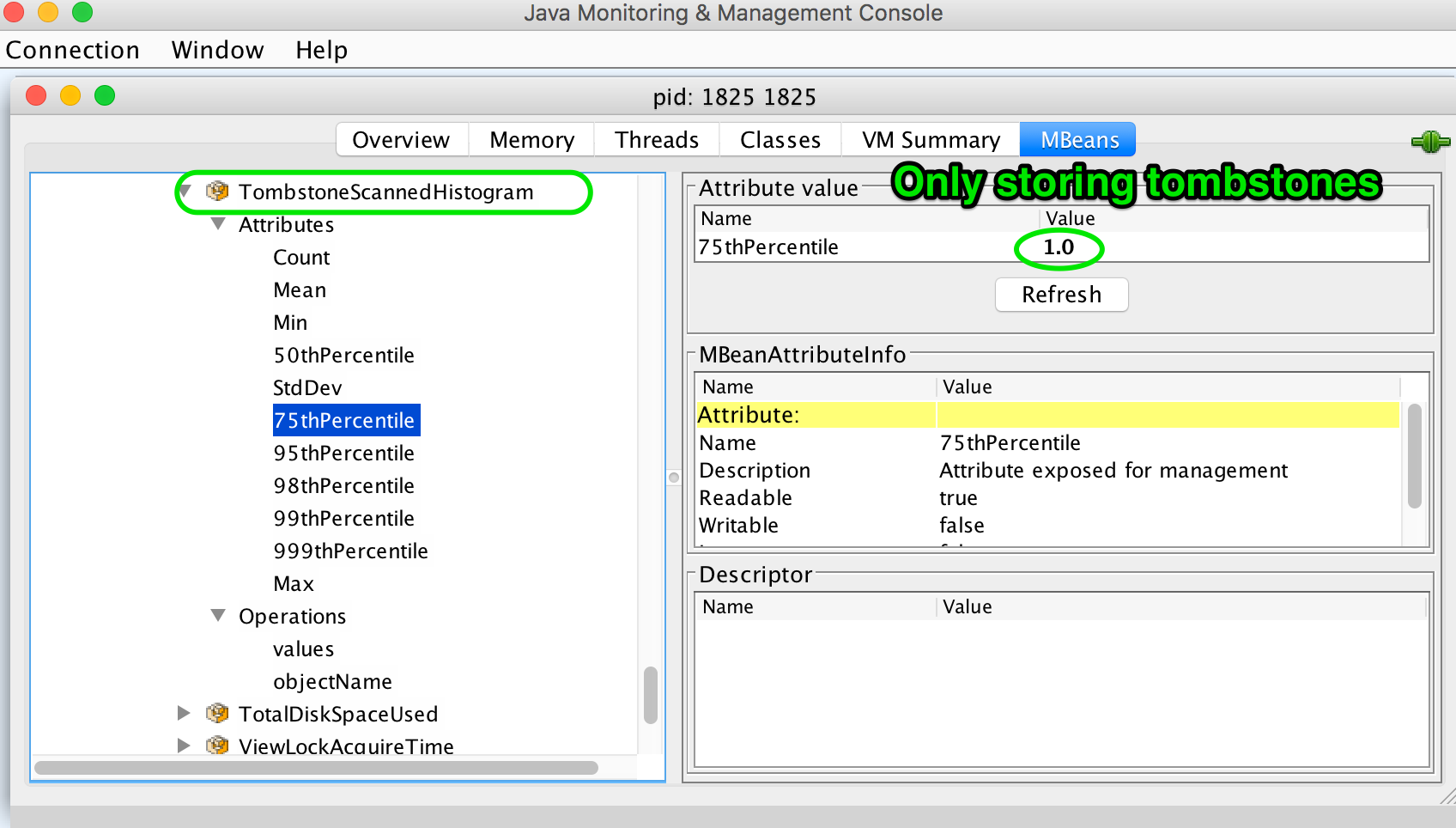
Single SSTable compaction
Single SSTable compactions were introduced in Cassandra 1.2, after Jonathan Ellis reported the following in CASSANDRA-3442:
Under size-tiered compaction, you can generate large SSTables that compact infrequently. With expiring columns mixed in, we could waste a lot of space in this situation.
As mentioned above, compactions are responsible for tombstone evictions. Under certain circumstances, compactions are not doing a good job evicting tombstones. This is not only true for STCS as mentioned in this ticket from the old days, but it is also true with all the compaction strategies. Some SSTables can be compacted very infrequently or have overlapping SSTables for a very long time. That is why, nowadays, all the compaction strategies come with a set of parameters to help with tombstone eviction.
tombstone_threshold: This setting does exactly what Jonathan Ellis described in 2011 in his ticket.
If we kept a TTL EstimatedHistogram in the SSTable metadata, we could do a single-SSTable compaction against SSTables with over 20% expired data.
So when the droppable tombstone ratio is considered to be above X (X = 0.2, 20% by default), this option triggers a single SSTable compaction, to take care of the tombstones that can be evicted, often less than the estimated, since the calculated tombstone ratio do not consider gc_grace_seconds.
tombstone_compaction_interval: This option was introduced in CASSANDRA-4781 to solve an infinite loop issue that was happening when the compaction ratio was high enough to trigger a single-SSTable compaction, but that tombstones were not evicted due to overlapping SSTables. We have to make sure to remove all the data shards to avoid zombies. In this case, compaction was continuously happening on some SSTables. As the single-SSTable compaction is triggered based on a tombstone ratio that is an estimation, this option make the minimum interval between 2 single-SSTable compaction tunable, default is 1 day.
unchecked_tombstone_compaction: Introduced by Paulo Motta in CASSANDRA-6563. Here is what he says about single-SSTable history and the reason he introduced this parameter, which is very interesting and I couldn’t explain it any better.
Just be aware of the trade-off: setting this option to true will trigger a single-SSTable compaction every day (tombstone_compaction_interval default), as soon as the tombstone ratio (estimation) is higher than 0.2 (20% of the data are tombstones, tombstone_threshold default), even if none of the tombstones are actually droppable. This would be the worst case.
So the trade-off is spending some resources to have a better tombstone eviction, hopefully.
Recommendation: giving this option a try as soon as some datacenter is having troubles removing tombstones should be worth it. I have had some successful experiences using this option and no real bad experiences, but rather a few situations where this change had no real impact. I even had some 100% full nodes going down to more decent levels after setting this option to true and/or compacting the right SSTables manually.
To alter any of those settings, describe the table you want to alter and rewrite the whole compaction strategy to avoid any issue. To change compaction options for the table tombstones in the tlp_lab keyspace, I would do this:
MacBook-Pro:~ alain$ echo "DESCRIBE TABLE tlp_lab.tombstones;" | cqlsh
CREATE TABLE tlp_lab.tombstones (
fruit text,
date text,
crates set<int>,
PRIMARY KEY (fruit, date)
) WITH CLUSTERING ORDER BY (date ASC)
AND bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
Then I copy the compaction options and alter the table as follow:
echo "ALTER TABLE tlp_lab.tombstones WITH compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4', 'unchecked_tombstone_compaction': 'true', 'tombstone_threshold': '0.1'};" | cqlsh
Or put the script in a file and execute it:
ALTER TABLE tlp_lab.tombstones WITH compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4', 'unchecked_tombstone_compaction': 'true', 'tombstone_threshold': '0.1'};
cqlsh -f myfile.cql
or even use -e option
cqlsh -e "ALTER TABLE tlp_lab.tombstones WITH compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4', 'unchecked_tombstone_compaction': 'true', 'tombstone_threshold': '0.1'};"
Note: I use one of those options rather than entering the cqlsh console because it is easier to pipe the output to work on it. It makes more sense when selecting data or describing tables. Imagine you need to check the read_repair_chance on all your tables:
MacBook-Pro:~ alain$ echo "DESCRIBE TABLE tlp_lab.tombstones;" | cqlsh | grep -e TABLE -e read_repair_chance
CREATE TABLE tlp_lab.tombstones (
AND dclocal_read_repair_chance = 0.1
AND read_repair_chance = 0.0
CREATE TABLE tlp_lab.foo (
AND dclocal_read_repair_chance = 0.0
AND read_repair_chance = 0.1
CREATE TABLE tlp_lab.bar (
AND dclocal_read_repair_chance = 0.0
AND read_repair_chance = 0.0
Evicting tombstones manually
Sometimes some SSTables contain 95% of tombstones and are still not triggering any compaction due to the compactions options, the overlapping sstables, or just the fact that single-SSTable compactions have a lower priority than regular compactions. It is important to know that we can manually force Cassandra to run a User Defined Compaction. To do it we need to be able to send commands through JMX. So I will be considering jmxterm here. Use what you prefer.
To set up jmxterm:
wget http://sourceforge.net/projects/cyclops-group/files/jmxterm/1.0-alpha-4/jmxterm-1.0-alpha-4-uber.jar
Then run JMX commands, like forcing a compaction:
echo "run -b org.apache.cassandra.db:type=CompactionManager forceUserDefinedCompaction myks-mytable-marker-sstablenumber-Data.db" | java -jar jmxterm-1.0-alpha-4-uber.jar -l localhost:7199
In some cases I have used scripts based on this kind of command combined with the tombstone ratio given by the sstablemetadata tool to search the worst files in term of tombstone ratio and have them compacting, quite successfully.
Conclusion
Deletes have always been a tricky operation to perform against a distributed system, particularly when trying to simultaneously manage availability, consistency, and durability.
Using tombstones is a smart way of performing deletes in a distributed system like Apache Cassandra, but it comes with some caveats. We need to think in a non-intuitive way as adding this piece of data is not a natural thing, when deleting. Then understand the life cycle of the tombstones, which isn’t trivial either. Yet, it gets easier to reason about tombstones when we understand their behavior and use the appropriate tooling to help us solve tombstone issues.
As Cassandra is a quickly evolving system, here are some ongoing tickets around tombstones you might be interested to know about.
Open tickets:
CASSANDRA-7019: Improve tombstone compactions (Mainly solving the overlapping SSTable tombstone eviction, by having single-SSTable compactions actually running on multiple smartly chosen SSTables). CASSANDRA-8527: Account for range tombstones wherever we account for tombstones. It looks like range tombstones might not be well considered in multiple parts of the code. CASSANDRA-11166 and CASSANDRA-9617 also point at this issue.